
niusouti.com
更多“给出四叉树的生成算法?”相关问题
-
第1题:
对于给出一组权W={2,4,5,9},通过霍夫曼算法求出的扩充二叉树的带权外部路径长度为__________。
正确答案:
37
按照霍夫曼树构造的方法构造一棵带权的扩充二叉树,此扩充二叉树的带权外部路径长度为9×1+5×2+(2+4)×3=37。 -
第2题:
试写一个判别给定二叉树是否为二叉排序树的算法。参考答案:根据二叉排序树中序遍历所得结点值为增序的性质,在遍历中将当前遍历结点与其前驱结点值比较,即可得出结论,为此设全局指针变量pre(初值为null)和全局变量flag,初值为true。若非二叉排序树,则置flag为false。
[算法描述]
#define true 1
#define false 0
typedef struct node
{datatype data; struct node *lchild,*rchild;} *BTree;
void JudgeBST(BTree T,int flag)
// 判断二叉树是否是二叉排序树,本算法结束后,在调用程序中由flag得出结论。
{ if(T!=null && flag)
{ Judgebst(T->lchild,flag);// 中序遍历左子树
if(pre==null)pre=T;// 中序遍历的第一个结点不必判断
else if(pre->datadata)pre=T;//前驱指针指向当前结点
else{flag=flase;} //不是完全二叉树
Judgebst (T->rchild,flag);// 中序遍历右子树
}//JudgeBST算法结束
-
第3题:
给出叶赋权m叉树的定义,并求叶赋权分别为2,3,5,7,8的最优2叉树。答案:定义:设G=(V,E)是一颗根数,若max deg+(v)=m,则称G是m叉树(m-ary tree)。
对于2,3,5,7,8先组合两个最小的权2+3=5,嘚,5,5,7,8,在所得序列中再组合5+5=10,重新排列后为7,8,10,在组合7+8=15,得10,15,最后组合10+15=25。
2 3 5 7 8
5 5 7 8
10 7 8
10 15
25
所求的最优二叉树如下:
-
第4题:
算法与编程
1、说明生活中遇到的二叉树,用java 实现二叉树
正确答案:我有很多个(假设10 万个)数据要保存起来,以后还需要从保存的这些数据中检索是否存在
某个数据,(我想说出二叉树的好处,该怎么说呢?那就是说别人的缺点),假如存在数组中,
那么,碰巧要找的数字位于99999 那个地方,那查找的速度将很慢,因为要从第1 个依次往
后取,取出来后进行比较。平衡二叉树(构建平衡二叉树需要先排序,我们这里就不作考虑
了)可以很好地解决这个问题,但二叉树的遍历(前序,中序,后序)效率要比数组低很多,
原理如下图:
代码如下:
package com.huawei.interview;
public class Node {
public int value;
public Node left;
public Node right;
public void store(int value)
{
if(value<this.value)
{
if(left == null)
{
left = new Node();
left.value=value;
}
else
{
left.store(value);
}
}
else if(value>this.value)
{
if(right == null)
{
right = new Node();
right.value=value;
}
else
{
right.store(value);
}
}
}
public boolean find(int value)
{
System.out.println("happen " + this.value);
if(value == this.value)
{
return true;
}
else if(value>this.value)
{
if(right == null) return false;
return right.find(value);
}else
{
if(left == null) return false;
return left.find(value);
}
}
public void preList()
{
System.out.print(this.value + ",");
if(left!=null) left.preList();
if(right!=null) right.preList();
}
public void middleList()
{
if(left!=null) left.preList();
System.out.print(this.value + ",");
if(right!=null) right.preList();
}
public void afterList()
{
if(left!=null) left.preList();
if(right!=null) right.preList();
System.out.print(this.value + ",");
}
public static void main(String [] args)
{
int [] data = new int[20];
for(int i=0;i<data.length;i++)
{
data[i] = (int)(Math.random()*100) + 1;
System.out.print(data[i] + ",");
}
System.out.println();
Node root = new Node();
root.value = data[0];
for(int i=1;i<data.length;i++)
{
root.store(data[i]);
}
root.find(data[19]);
root.preList();
System.out.println();
root.middleList();
System.out.println();
root.afterList();
}
}
1、从类似如下的文本文件中读取出所有的姓名,并打印出
重复的姓名和重复的次数,并按重复次数排序:
1,张三,28
2,李四,35
3,张三,28
4,王五,35
5,张三,28
6,李四,35
7,赵六,28
8,田七,35
程序代码如下(答题要博得用人单位的喜欢,包名用该公司,面试前就提前查好该公司
的网址,如果查不到,现场问也是可以的。还要加上实现思路的注释):
package com.huawei.interview;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.TreeSet;
public class GetNameTest {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
//InputStream ips =
GetNameTest.class.getResourceAsStream("/com/huawei/interview/info.txt
");
//用上一行注释的代码和下一行的代码都可以,因为info.txt与GetNameTest类在
同一包下面,所以,可以用下面的相对路径形式
Map results = new HashMap();
InputStream ips =
GetNameTest.class.getResourceAsStream("info.txt");
BufferedReader in = new BufferedReader(new
InputStreamReader(ips));
String line = null;
try {
while((line=in.readLine())!=null)
{
dealLine(line,results);
}
sortResults(results);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
static class User
{
public String name;
public Integer value;
public User(String name,Integer value)
{
this.name = name;
this.value = value;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
//下面的代码没有执行,说明往treeset中增加数据时,不会使用到equals方
法。
boolean result = super.equals(obj);
System.out.println(result);
return result;
}
}
private static void sortResults(Map results) {
// TODO Auto-generated method stub
TreeSet sortedResults = new TreeSet(
new Comparator(){
public int compare(Object o1, Object o2) {
// TODO Auto-generated method stub
User user1 = (User)o1;
User user2 = (User)o2;
/*如果compareTo返回结果0,则认为两个对象相等,新的对象不
会增加到集合中去
* 所以,不能直接用下面的代码,否则,那些个数相同的其他姓
名就打印不出来。
* */
//return user1.value-user2.value;
//return
user1.value<user2.value?-1:user1.value==user2.value?0:1;
if(user1.value<user2.value)
{
return -1;
}else if(user1.value>user2.value)
{
return 1;
}else
{
return user1.name.compareTo(user2.name);
}
}
}
);
Iterator iterator = results.keySet().iterator();
while(iterator.hasNext())
{
String name = (String)iterator.next();
Integer value = (Integer)results.get(name);
if(value > 1)
{
sortedResults.add(new User(name,value));
}
}
printResults(sortedResults);
}
private static void printResults(TreeSet sortedResults)
{
Iterator iterator = sortedResults.iterator();
while(iterator.hasNext())
{
User user = (User)iterator.next();
System.out.println(user.name + ":" + user.value);
}
}
public static void dealLine(String line,Map map)
{
if(!"".equals(line.trim()))
{
String [] results = line.split(",");
if(results.length == 3)
{
String name = results[1];
Integer value = (Integer)map.get(name);
if(value == null) value = 0;
map.put(name,value + 1);
}
}
}
}
-
第5题:
下列给出的方法中,适合生成DEM的是 ( )A.等高线数字化法
B.多边形环路法
C.四叉树法
D.拓扑结构编码法答案:A解析:DEM是指数字高程模型。要生成DEM就需要碎步点的高程,四个选项中只有选项A可以提供点的高程。 -
第6题:
按照二叉树的递归定义,对二叉树遍历的常用算法有()、()、()三种。
先序;中序;后序
略 -
第7题:
给出不同的输入序列建造二叉排序树,一定得到不同的二叉排序树。
正确答案:正确 -
第8题:
对于给出的一组仅w={5,6,8,12},通过霍夫曼算法求出的扩充二叉树的带权外部路径长度为()。
正确答案:118 -
第9题:
下列给出的方法中,哪项适合生成DEM()。
- A、空间数据内插法
- B、多边形环路法
- C、四叉树法
- D、拓扑结构编码法
正确答案:A -
第10题:
单选题下列给出的方法中,()适合生成DEM。A等高线数字化法
B多边形环路法
C四叉树法
D拓扑结构编码法
正确答案: C解析: 暂无解析 -
第11题:
问答题给出四叉树的生成算法?正确答案: A.整个图象作为四叉树的根结点,进行四等分,形成四个子结点;
B.对四个子结点进行检查,确定结点属性(黑色、白色、灰色),存入堆栈Stack;
C.若栈非空,则执行(d);否则结束;
D.若结点为灰色,则平分对应的区域,同时从该结点分叉出四个结点,重复步骤(b)。解析: 暂无解析 -
第12题:
填空题按照二叉树的递归定义,对二叉树遍历的常用算法有()、()、()三种。正确答案: 先序,中序,后序解析: 暂无解析 -
第13题:
下面哪些使用的不是贪心算法()
A.单源最短路径中的Dijkstra算法
B.最小生成树的Prim算法
C.最小生成树的Kruskal算法
D.计算每对顶点最短路径的Floyd-Warshall算法
正确答案:D
-
第14题:
给出下列二叉树的前序序列【 】。
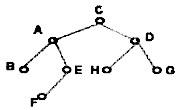 正确答案:ABEFDHG
正确答案:ABEFDHG
ABEFDHG -
第15题:
编写递归算法,求以二叉链表存储的二叉树的深度。参考答案:
-
第16题:
若采用孩子兄弟链表作为树的存储结构,则树的后序遍历应采用二叉树的 ( )
A.层次遍历算法
B.前序遍历算法
C.中序遍历算法
D.后序遍历算法
正确答案:C
-
第17题:
下列给出的方法中,适合生成DEM的是()A:等高线数字化法
B:多边形环路法
C:四叉树法
D:拓扑结构编码法答案:A解析:DEM是指数字高程模型。要生成DEM就需要碎步点的高程,四个选项中只有选项A可以提供点的高程。 -
第18题:
数据结构与算法里,二叉排序树的右子树也应该是棵二叉排序树
正确答案:正确 -
第19题:
数据结构与算法里,关于二叉排序树的递归性说法对的是()。
- A、二叉排序树的左子树也是任意二叉树
- B、二叉排序树的左子树也是二叉排序树
- C、二叉排序树的左子树也是普通树
- D、二叉排序树的左子树也是普通二叉排序树
正确答案:B -
第20题:
什么是栅格四叉树结构?请比较常规四叉树与线性四叉树的区别?
正确答案: 栅格四叉树结构是指将空格键区域按照四个象限进行递归分n次,每次分割形成2n*2N个子象限中的属性数值都相同为止,该子象限就不再分割。
常规四叉树与线性四叉树的区别:常规四叉树:常规四叉树每个节点通常储存6个量,即4个子节点指针、一个父节点指针和一个节点值。常规四叉树可采用子下而上的方法建立,对栅格按莫顿码顺序进行检测,这种方法除了要记录叶节点,还要记录中间节点。常规四叉树在处理上简便灵活,而且当栅格矩阵很大,存储和处理整个矩阵较困难时,可用常规四叉树存储法;
线性四叉树:线性四叉树每个节点只存储3个量,即莫顿码、深度(或节点大小)和节点值。线性四叉树编码不需要记录中间节点的、0值节点,也不适用指针,仅记录非0值也节点,并用莫顿码表示叶节点的位置。线性四叉树比常规四叉树节省存储空间;由于记录节点地址,既能直接找到其在四叉树中的走向路径,又可以换算出他在整个栅格区域内的行列位置,压缩和解压缩比较方便,各部分分辨率可不同,即可精确地表示图形结构,又可减少存储量,易于进行大部分图形操作和运算。 -
第21题:
单选题下列给出的方法中,哪项适合生成DEM()。A空间数据内插法
B多边形环路法
C四叉树法
D拓扑结构编码法
正确答案: A解析: 暂无解析 -
第22题:
填空题对于给出的一组权{10,12,16,21,30},通过霍夫曼算法求出的扩充二叉树的带权外部路径长度为()。正确答案: 200解析: 暂无解析 -
第23题:
问答题什么是栅格四叉树结构?请比较常规四叉树与线性四叉树的区别?正确答案: 栅格四叉树结构是指将空格键区域按照四个象限进行递归分n次,每次分割形成2n*2N个子象限中的属性数值都相同为止,该子象限就不再分割。
常规四叉树与线性四叉树的区别:常规四叉树:常规四叉树每个节点通常储存6个量,即4个子节点指针、一个父节点指针和一个节点值。常规四叉树可采用子下而上的方法建立,对栅格按莫顿码顺序进行检测,这种方法除了要记录叶节点,还要记录中间节点。常规四叉树在处理上简便灵活,而且当栅格矩阵很大,存储和处理整个矩阵较困难时,可用常规四叉树存储法;
线性四叉树:线性四叉树每个节点只存储3个量,即莫顿码、深度(或节点大小)和节点值。线性四叉树编码不需要记录中间节点的、0值节点,也不适用指针,仅记录非0值也节点,并用莫顿码表示叶节点的位置。线性四叉树比常规四叉树节省存储空间;由于记录节点地址,既能直接找到其在四叉树中的走向路径,又可以换算出他在整个栅格区域内的行列位置,压缩和解压缩比较方便,各部分分辨率可不同,即可精确地表示图形结构,又可减少存储量,易于进行大部分图形操作和运算。解析: 暂无解析