
niusouti.com
自学考试报名过程中有个“记录报名单”的加工。该加工主要是根据报名表(姓名、性别、身份证号、课程名)和开考课程(课程名、开考时间)、经校核,编号、填写、输出准考证给报名者,同时记录到考生名册中(准考证号、姓名、课程)。请绘制该加工的DFD图,并写出数据词典中的数据流条目。
题目
自学考试报名过程中有个“记录报名单”的加工。该加工主要是根据报名表(姓名、性别、身份证号、课程名)和开考课程(课程名、开考时间)、经校核,编号、填写、输出准考证给报名者,同时记录到考生名册中(准考证号、姓名、课程)。请绘制该加工的DFD图,并写出数据词典中的数据流条目。
相似考题
更多“自学考试报名过程中有个“记录报名单”的加工。该加工主要是根据报名表(姓名、性别、身份证号、课程 ”相关问题
-
第1题:
在“考试报名表.mdb”数据库中有“考试报名表”。
(1)将“考试报名表”表的列宽设置为13,单元格效果改为“凸起”。“考试报名表”表如图所示。
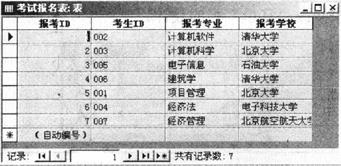
(2)按照下列要求创建“考生”表,并输入以下数据。
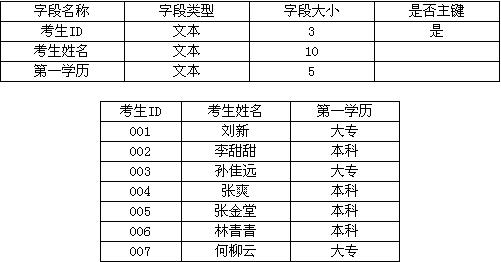
“考生”表如图所示。
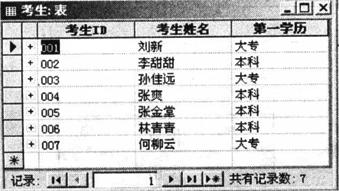
(3)设置考生表和考生报名表的关系为一对多,实施参照完整性,级联更新相关字段,级联删除相关记录。
正确答案:
-
第2题:
设有来自三个地区的各10名、15名和25名考生的报名表,其中女生的报名表分别为3份、7份和5份,随机取出一个地区,再从中抽取两份报名表.
(1)求先抽到的一份报名表是女生表的概率p;
(2)设后抽到的一份报名表为男生的报名表,求先抽到的报名表为女生报名表的概率q.答案:解析:
-
第3题:
2、问题域中有一个类“学生”,其中的属性有:学号、姓名、性别、生日,籍贯、照片、身份证号、出生证明。现在有一个可复用的类“学生”,其中的属性有:学号、姓名、性别、年龄,籍贯,该如何进行复用类处理?
ABCD -
第4题:
●试题一
阅读下列说明和数据流图,回答问题1~问题3。
【说明】
某考务处理系统主要功能是考生管理和成绩管理:
1.对考生送来的报名表进行检查。
2.对合格的报名表编好准考证号码后将准考证送给考生,将汇总后的考生名单送给阅卷站。
3.对阅卷站送来的成绩表进行检查,并根据考试中心指定的合格标准审定合格者。
4.填写考生通知单(内容包含该考生的准考证号、姓名、各课程成绩及最终合格/不合格标志),送给考生。
5.根据考生信息及考试成绩,按地区、年龄、文化程度和职业进行成绩分类统计及试题难度分析,产生统计分析表。
考务处理系统的顶层图如图1所示,第0层图如图2所示,加工2子图如图3所示。
【数据流图】
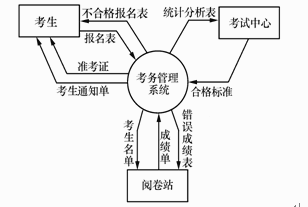
图1顶层图
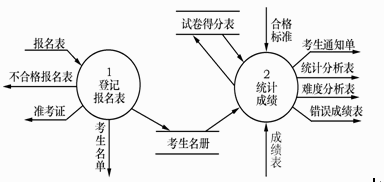
图2 0层图
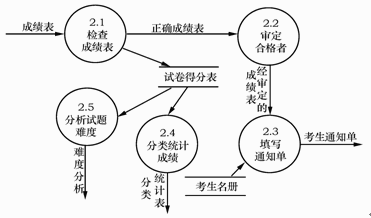
图3加工2子图
【问题1】
指出哪张图的哪些文件可以不必画出。
【问题2】
数据流图1-3中缺少3条数据流,请直接在图中添加。
【问题3】
根据系统功能和数据流图填充下列数据字典条目中的 (1) 和 (2) :
试题得分表=准考证号+{课程名+成绩}
考生名册=报名号+准考证号+姓名+通信地址+出生年份+文化程度+职业
考生通知单= (1)
报名表= (2)
正确答案:
●试题一[问题1]【答案】0层图中的"试卷得分表"是局部文件,可不必画出。[问题2]【答案】(1)分类统计成绩中需要读入考生成绩,缺少从"考生名册"到"2.4分类统计成绩"的数据流。(2)"2.1检查成绩表"缺少输出数据流"错误成绩表"。(3)"2.2审定合格者"缺少输入数据流"合格标准"。[问题3]【答案】(1)准考证号+姓名+{课程名+成绩}+合格/不合格标志(2)报名号+姓名+通信地址+出生年份+文化程度+职业【解析】问题1中"不必画出"是指在某层数据流图中,只画流程图中各加工之间的公共数据文件,隐藏某加工的局部数据文件,这个规则只是为了使整个数据流图的层次结构更科学、更清晰,不过画出"不必画出的数据文件"对数据流图不会造成理解错误。在0层图中有文件"考生名册"和"试卷得分表",其中"试卷得分表"是加工2"统计成绩"的局部数据文件,所以不必画出。问题2是要指出哪些图中遗漏了哪些数据流,这需要从两个方面进行考虑:一是父图与子图的平衡,即子图的输入、输出数据流与父图相应的加工的输入、输出数据必须一致。二是针对每个加工至少要有一个输入和输出,反映次加工的数据来源和结果。数据流图1-3是加工2"统计成绩"的子图,为了发现图中遗漏的数据流,首先要观察0层图中加工2的输入、输出流。在O层图中,加工2"统计成绩"有2个输入流"合格标准"和"成绩表",4个输出流"考生通知单"、"统计分析表"、"难度分析表"和"错误成绩表"。再看加工2子图中只有一个输入流"成绩表",可见必然遗漏了一个输入流"合格标准"。根据题目说明提到的"对阅卷站送来的成绩表进行检查,并根据考试中心指定的合格标准审定合格者",所以输入流"合格标准"应该是输入到加工2.2"审定合格者"。加工2子图中只有3个输出流"考生通知单"、"统计分析表"和"难度分析表",缺少数据流"错误成绩表"。加工2.1"检查成绩表"的功能是检查成绩表是否合格,其中一个输出流是"正确成绩表",自然另一个是输出是"错误成绩表"。因此,第二个遗漏的数据流是"2.1检查成绩表"的输出数据流"错误成绩表"。根据题目中提到的"根据考生信息及考试成绩,按地区、年龄、文化程度和职业进行成绩分类统计及试题难度分析,产生统计分析表"这一说明,可以判断出加工2.4"分类统计成绩"除了需要"试卷得分表"的输入流外,还需要考生信息,需要从文件"考生名册"中输入。问题3中根据题目说明中提到的"填写考生通知单(内容包含该考生的准考证号、姓名、各课程成绩及最终合格/不合格标志),送给考生",所以考生通知单应该包括考生的准考证号、姓名和最终合格/不合格标志,这种共同组成的含义由符号"+"来表示。同时因为考试可能有多门课程共同组成,所以,课程号和该课程的成绩也是必须的。其中的多门课程由符号"{…}"来表示重复。因此,考生通知单=准考证号+姓名+{课程名+成绩}+合格/不合格标志。根据题目说明中提到的"对合格的报名表编好准考证号码后将准考证送给考生",在0层图中可以看到,加工1"登记报名表"把考生信息写入文件"考生名册"中,可见"考生名册"中的数据除"准考证号"外均从合格的报名表中得到。因此"报名表"至少需要由报名号、姓名、通信地址、出生年份、文化程度和职业组成。由数据字典定义式表示为:报名表=报名号+姓名+通信地址+出生年份+文化程度+职业。 -
第5题:
5、5、关系模式:学生(学号,姓名,性别,身份证号,籍贯,所在系)。则该关系模式的非主属性有()。
A.学号
B.姓名、性别
C.籍贯、所在系
D.身份证号
√