
niusouti.com
堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则( )是一个小顶堆结构。堆结构用二叉树表示,则适宜的二叉树类型为( )。对于10个结点的小顶堆,其对应的二叉树的高度(层数)为( )。堆排序是一种基于堆结构的排序算法,该算法的时间复杂度为(请作答此空)。A.lgn B.nlgn C.n D.n2
题目
B.nlgn
C.n
D.n2
相似考题
更多“堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则( )是一个小顶堆结构。堆结构用二叉树表示,则适宜的二叉树类型为( )。对于10个结点的小顶堆,其对应的二叉树的高度(层数)为( )。堆排序是一种基于堆结构的排序算法,该算法的时间复杂度为(请作答此空)。”相关问题
-
第1题:
对于序列{26,33,35,29,19,12,22}, (1)判断它是否是堆,若是,写出其是大顶堆还是小顶堆;若不是,把它调整为堆,写出调整的过程和调整后的序列。 (2)写出对该序列进行直接插入排序每一趟结束时的关键字状态。参考答案:
-
第2题:
对于n个元素的关键字序列{k1,k2,…,kn},若将其按次序对应到一棵具有n个结点的完全二叉树上,使得任意结点都不大于其孩子结点(若存在孩子结点),则称其为小顶堆。根据以上定义,(43)是小顶堆。
A.
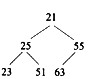
B.
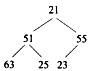
C.
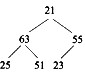
D.
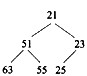 正确答案:D
正确答案:D
解析:本题考查排序方法中堆排序的基础知识。,对于n个元素的关键字序列{k1,k2,…,kn},当且仅当满足下列关系时称其为堆:①ki≤k2i且ki≤k2i+1或者②kik2i且kik2i+1其中,1≤i≤|n/2|,满足①式称为小顶堆,满足②式称为大顶堆。显然,题目中选、项A中25与23和51之间的关系不满足小顶堆的定义;选项B中51与63和25之间、 55与23之间的关系不满足小顶堆的定义;选项C的情况与B类似。选项D是小顶堆。 -
第3题:
对于n个元素的关键字序列K1,K2,…,Kn,若有Ki≤K2i≤且Ki≤2i+1(i=1,2,…,[n/2],2i+1≤n),则称其为小根堆。以下关于小根堆及其元素关系的叙述中,错误的是( )。
A.关键字序列K1,K2,…,Kn呈非递减排序时一定为小根堆
B.小根堆中的序列K1,K2,K4…,K2j(2j≤n)一定为非递减序列
C.小根堆中元素K2i与K2i+1(2i≤n,2i+1≤n)之间的大小关系不能确定
D.小根堆的最后一个元素一定是序列的最大元素
正确答案:D
解析:小根堆中元素比它本身的根小,它和它的兄弟没有大小关系。 -
第4题:
中从任一结点出发到根的路径上,所经过的结点序列必按其关键字降序排列。
A.二叉排序树
B.大顶堆
C.小顶堆
D.最优二叉树
正确答案:C
-
第5题:
● 堆是一种有用的数据结构,堆排序是一种选择排序,它的一个基本问题是如何造堆,常用的建堆方法是 1964年Floyd提出的渗透法。采用此方法对 n个元素进行排序时,堆排序的时间复杂性是 (53) 。
(53)
A. O(nLog2n)
B. O(n)
C. O(Log2n)
D. O(n2)
正确答案:A
-
第6题:
在含有n个关键字的小根堆(堆顶元素最小)中,关键字最大的记录有可能存储的位置是()。 答案:D解析:
答案:D解析:
-
第7题:
堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则____1__是一个大顶堆结构,该堆结构用二叉树表示,其高度(或层数)为___2___。
1、_____A.94,31,53,23,16,27
B.94,53,31,72,16,23
C.16,53,23,94,31,72
D.16,31,23,94,53,72答案:A解析:本题考查数据结构的基础知识。 在进行软件开发的详细设计阶段,数据结构设计是重要的内容,考生应该了解常用的数据结构。 堆是一个应用非常广泛的数据结构,根据题干给出的说明,可知A是一个大顶堆,用二叉树表示如下。该二叉树高度为3。
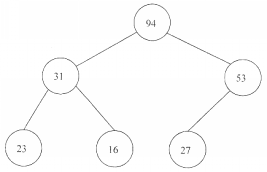
-
第8题:
堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则( )是一个小顶堆结构。堆结构用二叉树表示,则适宜的二叉树类型为(请作答此空)。对于10个结点的小顶堆,其对应的二叉树的高度(层数)为( )。堆排序是一种基于堆结构的排序算法,该算法的时间复杂度为( )。A.普通二叉树
B.完全二叉树
C.二叉排序树
D.满二叉树答案:B解析:将元素按照层次遍历的方式压入二叉树,只有选项A满足小顶堆的要。求小顶堆是一种经过排序的完全二叉树,对于一个完全二叉树,第1层为最多1个结点,第2层最多2个结点,第n层最多2^ (n- 1 )个结点,本题1 0个结点=1 +2+4+3 ,所以需要4层

-
第9题:
优先队列通常采用(请作答此空)数据结构实现,向优先队列中插入—个元素的时间复杂度为( )。A.堆
B.栈
C.队列
D.线性表答案:A解析:本题考查数据结构基础知识。普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出(largest-in,first-out)的行为特征。优先队列一般采用二叉堆数据结构实现,由于是二叉堆,所以插入和删除一个元素的时间复杂度均为O(lgn)。本题依次选A、C选项。 -
第10题:
()从二叉树的任一结点出发到根的路径上,所经过的结点序列必按其关键字降序排列。
- A、二叉排序树
- B、大顶堆
- C、小顶堆
- D、平衡二叉树
正确答案:C -
第11题:
单选题在含有n个关键字的小根堆(堆顶元素最小)中,关键字最大的记录有可能存储在( )位置上。A∣n/2∣
B∣n/2∣
C1
D∣n/2∣+2
正确答案: C解析: -
第12题:
填空题在一个小根堆中,堆顶结点的值是所有结点中的(),在一个大根堆中,堆顶结点的值是所有结点中的()。正确答案: 最小值,最大值解析: 暂无解析 -
第13题:
● 对于n 个元素的关键字序列{k1,k2,…,kn}, 若将其按次序对应到一棵具有 n 个结点的完全二叉树上, 使得任意结点都不大于其孩子结点(若存在孩子结点), 则称其为小顶堆。根据以上定义, (43) 是小顶堆
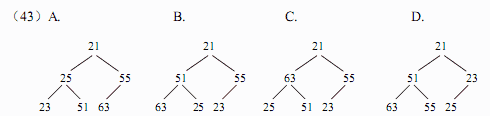 正确答案:D
正确答案:D
-
第14题:
______从二叉树的任一节点出发到根的路径上,所经过的节点序列必须按其关键字降序排列。
A.二叉排序树
B.大顶堆
C.小顶堆
D.平衡二又树
正确答案:C
解析:n0是度为0的节点总数(即叶子节点数),n1是度为l的节点总数,n2是度为2的节点总数,由二叉树的性质可知:n0=n2+1,则完全二叉树的节点总数n为:n=n0+n1+n2,由于完全二叉树中度为1的节点数只有两种可能0或1,由此可得n0=(n+1)/2或n0=nJ2,合并成一个公式为:n0=(n+1)/2(注:此处表示整除),即可根据完全二又树的节点总数计算出叶子节点数。 -
第15题:
从二叉树的任一节点出发到根的路径上,所经过的节点序列必按其关键字降序排列。
A.二叉排序树
B.大顶堆
C.小顶堆
D.平衡二叉树
正确答案:C
解析:当堆为小顶堆时,任意一棵子树的根点比其左右子节点要小,所以从任意节点出发到根的路径上,所经过的节点序列必按其关键字降序排列。 -
第16题:
试题四(共15分)
阅读下列说明和C代码,回答问题1至问题 3,将解答写在答题纸的对应栏内。
【说明】
堆数据结构定义如下:
在一个堆中,若堆顶元素为最大元素,则称为大顶堆;若堆顶元素为最小元素,则称为小顶堆。堆常用完全二叉树表示,图4-1 是一个大顶堆的例子。
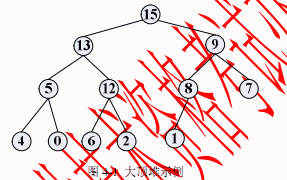
堆数据结构常用于优先队列中,以维护由一组元素构成的集合。对应于两类堆结构,优先队列也有最大优先队列和最小优先队列,其中最大优先队列采用大顶堆,最小优先队列采用小顶堆。以下考虑最大优先队列。
假设现已建好大顶堆A,且已经实现了调整堆的函数heapify(A, n, index)。
下面将C代码中需要完善的三个函数说明如下:
(1)heapMaximum(A):返回大顶堆A中的最大元素。
(2)heapExtractMax(A):去掉并返回大顶堆 A的最大元素,将最后一个元素“提前”到堆顶位置,并将剩余元素调整成大顶堆。
(3)maxHeapInsert(A, key):把元素key插入到大顶堆 A的最后位置,再将 A调整成大顶堆。
优先队列采用顺序存储方式,其存储结构定义如下:
define PARENT(i) i/2
typedef struct array{
int *int_array; //优先队列的存储空间首地址
int array_size; //优先队列的长度
int capacity; //优先队列存储空间的容量
} ARRAY;
【C代码】
(1)函数heapMaximum
int heapMaximum(ARRAY *A){ return (1) ; }
(2)函数heapExtractMax
int heapExtractMax(ARRAY *A){
int max;
max = A->int_array[0];
(2) ;
A->array_size --;
heapify(A,A->array_size,0); //将剩余元素调整成大顶堆
return max;
}
(3)函数maxHeapInsert
int maxHeapInsert(ARRAY *A,int key){
int i,*p;
if (A->array_size == A->capacity) { //存储空间的容量不够时扩充空间
p = (int*)realloc(A->int_array, A->capacity *2 * sizeof(int));
if (!p) return -1;
A->int_array = p;
A->capacity = 2 * A->capacity;
}
A->array_size ++;
i = (3) ;
while (i > 0 && (4) ){
A->int_array[i] = A->int_array[PARENT(i)];
i = PARENT(i);
}
(5) ;
return 0;
}
【问题 1】(10分)
根据以上说明和C代码,填充C代码中的空(1)~(5)。
【问题 2】(3分)
根据以上C代码,函数heapMaximum、heapExtractMax和 maxHeapInsert的时间复杂度的紧致上界分别为 (6) 、 (7) 和 (8) (用O 符号表示)。
【问题 3】(2分)
若将元素10插入到堆A =〈15, 13, 9, 5, 12, 8, 7, 4, 0, 6, 2, 1〉中,调用 maxHeapInsert函数进行操作,则新插入的元素在堆A中第 (9) 个位置(从 1 开始)。
正确答案:
试题四(共15分)【问题1】(10分,各2分)(1)A->int_array[0](2)A->int_array[0]=A->int_array[A->array_size-1](3)A->array_size-1(4)A->int_array[PARENT(i)]<key(5)A->int_array[i]=key【问题2】(3分,各1分)【问题3】(2分)(9)3 -
第17题:
堆排序是一种基于(请作答此空)的排序方法,()不是堆。A.计数
B.插入
C.选择
D.归并答案:C解析:堆排序是一种改进的选择排序方法。对于n个元素的关键字序列{k1,k2,…,kn},当且仅当满足下列关系时称其为堆:
若将此序列对应的一维数组(即以一维数组作为序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。对于题目中给出的四个序列分别构造完全二叉树,如下图所示。其中,(d)中的结点56,即不满足堆的定义。
-
第18题:
堆排序分为两个阶段,其中第一阶段将给定的序列建成一个堆,第二阶段逐次输出堆顶元素。设给定序列{48,62,35,77,55,14,35,98},若在堆排序的第一阶段将该序列建成一个堆(大根堆),那么交换元素的次数为()。A.5
B.6
C.7
D.8答案:B解析:
-
第19题:
堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则__1____是一个大顶堆结构,该堆结构用二叉树表示,其高度(或层数)为___2___。
2、_____A.2
B.3
C.4
D.5答案:B解析:本题考查数据结构的基础知识。 在进行软件开发的详细设计阶段,数据结构设计是重要的内容,考生应该了解常用的数据结构。 堆是一个应用非常广泛的数据结构,根据题干给出的说明,可知A是一个大顶堆,用二叉树表示如下。该二叉树高度为3。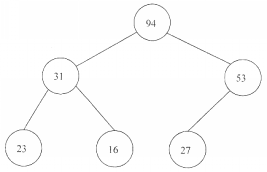
-
第20题:
堆是一种数据结构,分为大顶堆和小顶堆两种类型。大(小)顶堆要求父元素大于等于(小于等于)其左右孩子元素。则(请作答此空)是一个小顶堆结构。堆结构用二叉树表示,则适宜的二叉树类型为( )。对于10个结点的小顶堆,其对应的二叉树的高度(层数)为( )。堆排序是一种基于堆结构的排序算法,该算法的时间复杂度为( )。A.10,20,50,25,30,55,60,28,32,38
B.10,20,50,25,38,55,60,28,32,30
C.60,55,50,38,32,30,28,25,20,10
D.10,20,60,25,30,55,50,28,32,38答案:A解析:将元素按照层次遍历的方式压入二叉树,只有选项A满足小顶堆的要。求小顶堆是一种经过排序的完全二叉树,对于一个完全二叉树,第1层为最多1个结点,第2层最多2个结点,第n层最多2^ (n- 1 )个结点,本题1 0个结点=1 +2+4+3 ,所以需要4层

-
第21题:
利用筛选法,把序列{37,77,62,97,11,27,52,47}建成堆(小根堆),画出相应的完全二叉树,并写出对上述堆所对应的二叉树进行前序遍历得到的序列。
(1)
(2)11,37,47,97,77,27,62,52
略 -
第22题:
在一个小根堆中,堆顶结点的值是所有结点中的(),在一个大根堆中,堆顶结点的值是所有结点中的()。
正确答案:最小值;最大值 -
第23题:
单选题()从二叉树的任一结点出发到根的路径上,所经过的结点序列必按其关键字降序排列。A二叉排序树
B大顶堆
C小顶堆
D平衡二叉树
正确答案: C解析: 暂无解析
