
niusouti.com
下面关于分布式文件系统HDFS的描述正确的是A.分布式文件系统HDFS比较合适存储大量零碎的小文件B.分布式文件系统HDFS是谷歌分布式文件系统GFS(Google File System)的一种开源实现C.分布式文件系统HDFS是Google Bigtable的一种开源实现D.分布式文件系统HDFS是一种关系型数据库
题目
下面关于分布式文件系统HDFS的描述正确的是
A.分布式文件系统HDFS比较合适存储大量零碎的小文件
B.分布式文件系统HDFS是谷歌分布式文件系统GFS(Google File System)的一种开源实现
C.分布式文件系统HDFS是Google Bigtable的一种开源实现
D.分布式文件系统HDFS是一种关系型数据库
相似考题
更多“下面关于分布式文件系统HDFS的描述正确的是”相关问题
-
第1题:
hdfs文件系统适合随机读写。()此题为判断题(对,错)。
参考答案:×
-
第2题:
试题二(共25分)
阅读以下关于分布式存储系统设计的叙述,回答问题1至问题3。
某软件公司开发基于云计算的分布式文档协作平台( DDCP),系统部分需求如下所示:
(1)实现文档的分布式存储,客户端可随时随地上传和下载文档;
(2)支持多客户端并发编辑同一文档,某个客户端所做修改会实时显示在其他客户端;
(3)要求系统具有自我修复机制,当系统中某个节点失效时,无需人工干预能够自动实现节点替换并恢复到一致状态。
项目组经过讨论,决定采用现有的分布式文件系统作为基础架构,但在具体选用哪种设计方案时产生了分歧。王工建议采用Hadoop分布式文件系统HDFS作为系统参考架构,但张工认为Google分布式文件系统GFS更适合该系统需求。最后经过更为详细
的分析和讨论,同意了张工的建议,采用GFS作为分布式文档协作平台的文件系统架构。
【问题1】(12分)
请用300字以内的文字说明GFS和HDFS有何异同,并针对系统需求,用200字以内的文字说明选择GFS的原因。
【问题2】(8分)
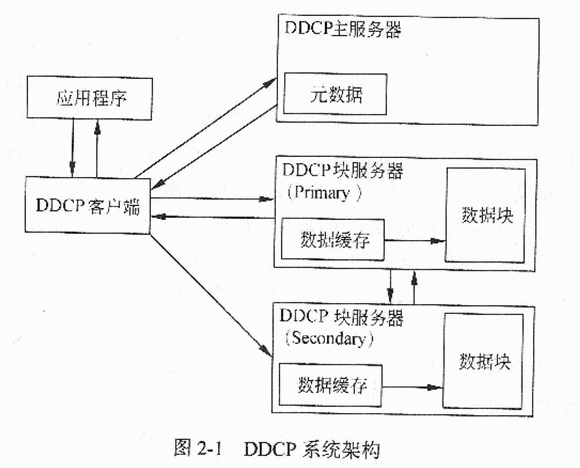
针对图2-1所示DDCP基础架构,请分别说明一次数据读操作和一次并发写操作的过程。
【问题3】(5分)
请分别叙述采用GFS和HDFS架构,单点失效问题是如何解决的。
正确答案:
试题二分析
分布式数据存储系统是实现云计算和面向服务计算等分布式计算模型的基础,采用不同的分布式文件系统架构决定了分布式数据存储系统的运行效率、可伸缩性、容错能力及安全性等。分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连,从而实现了数据的分布式存储和管理。
Google的GFS文件系统和Hadoop分布式文件系统HDFS是当前最流行的两种分布式文件系统参考架构。
本题主要考查应试者对于分布式文件系统设计的掌握情况,特别是GFS和HDFS分布式文件系统架构的设计。本题结合一个典型的实际项目案例,首先要求分析GFS和HDFS之间的异同,然后针对系统需求分析采用GFS文件系统的原因;针对项目中所设、计的DDCP基础架构,分析数据读写操作的过程;最后针对具体的单点失效问题,说明两种分布式文件系统架构所提供的解决方案。
【问题1】
本问题要求考生针对GFS和HDFS两种分布式文件系统架构的特点展开分析并进行总结。
(1) GFS是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统,虽然运行在多台普通硬件设备上,但是它提供了灾难冗余的能力,为大量客户机提供高性能的服务。一个GFS集群中包含了一个单独的Master节点、多台Chunk服务器,并且同时被多个客户端访问。GFS存储的文件被分割为固定大小的Chunk并分配标识,缺省提供3个存储复制节点,Master节点管理所有的文件系统元数据,GFS客户端代码以库的形式被链接到客户程序里,无论是客户端还是Chunk服务器都不需要缓存文件数据。
(2) HDF-S是一个高度容错性的系统,能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS采用Master/Slave架构,一个HDFS集群由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的命名空间以及客户端对文件的访问,集群中的Datanode 一般是一个节点一个,负责管理它所在节点上的存储。一个文件被分成一个或多个数据块,这些块存储在一组Datanodeh上,Namenode执行文件系统的命名空间操作并确定数据块到具体Datanode节点的映射,Datanode在Namenode的统一调度下负责处理文件系统客户端的读写请求。
【问题2】
本问题要求考生认真分析图中给出的DDCP系统架构,依据图中节点之间的数据传
输关系描述数据传输过程。
(1)读数据的过程:应用程序将读数据请求发送给客户端后,客户端访问主服务器请求所需数据位置信息,主服务器查询数据分块和地址信息返回给客户端,客户端根据地址信息向块服务器发送读数据请求,块服务器将所请求数据发送给客户端,客户端将数据转发给应用程序。
(2)写数据的过程:应用程序分别将数据和写数据请求发送给客户端,客户端依次访问主服务器请求所写数据位置信息,主服务器依次查询数据分块和地址信息发送给客户端,客户端将所要写入的数据重新组织,将属于同一个块服务器的数据按照分组报文和分组序列信息发送给块服务器数据缓存( Primary),客户端将所写数据按照分组报文发送给块服务器数据缓存( Secondary),块服务器数据缓存(Primary)按照分组序列将数据写入到块服务器数据块( Primary),块服务器(Primary)将分组序列发送给块服务器(Secondary),块服务器数据缓存(Secondary)按照分组序列将数据写入块服务器数据块( Secondary),块服务器(Secondary)将写入完成信息发送给块服务器(Primary),块服务器数据( Primary)将写数据完成信息发送给客户端。
【问题3】
本问题要求应试者掌握单点失效问题产生的原因,并能够结合GFS和HDFS架构的特点进行分析,说明所采用的解决方案。
参考答案
【问题1】
GFS与HDFS相比的相同点是:单一控制机和多台工作机;通过数据分块和复制实现可靠性和高性能;树状文件系统结构。
GFS与HDFS相比的不同点是:多次写入和多客户端并发增加数据;Master单点失效问题;数据快照的支持;实时性支持。
针对系统需求,文档协作要求多客户端并发写入文件支持;解决主服务器单点失效问题;系统补偿操作需要数据快照。
【问题2】
读数据过程:
④应用程序将读数据请求发送给DDCP客户端;
②DDCP客户端访问DDCP主服务器请求所需数据位置信息;
③DDCP主服务器查询数据分块和地址信息发送给DDCP客户端;
④DDCP客户端根据地址信息向DDCP块服务器发送读数据请求;
⑤DDCP块服务器将所请求数据发送给DDCP客户端;
⑥DDCP客户端将数据转发给应用程序。
并发写数据过程:
①并发写的应用程序分别将数据和写数据请求发送给DDCP客户端;
②DDCP客户端依次访问DDCP主服务器请求所写数据位置信息;
③DDCP主服务器依次查询数据分块和地址信息发送给DDCP客户端;
④DDCP客户端将所要写入的数据重新组织,将属于同一个DDCP块服务器的数
据按照分组报文和分组序列信息发送给DDCP块服务器数据缓存(Primary);
⑤DDCP客户端将所写数据按照分组报文发送给DDCP块服务器数据缓存
(Secondary);
⑥DDCP块服务器数据缓存(Primary)按照分组序列将数据写入到DDCP块服务
器数据块( Primary);
⑦DDCP块服务器(Primary)将分组序列发送给DDCP块服务器(Secondary);
⑧DDCP块服务器数据缓存(Secondary)按照分组序列将数据写入DDCP块服务
器数据块(Secondary);
⑨DDCP块服务器(Secondary)将写入完成信息发送给DDCP块服务器(Primary);
⑩DDCP块服务器数据(Primary)将写数据完成信息发送给DDCP客户端。
【问题3】
GFS中采用主从模式备份Master的系统元数据,当主Master失效时,可以通过分布式选举备机接替主Master继续对外提供服务,而由于复制及主备切换本身有一定的复杂性,HDFS Master的持久化数据只写入到本机(可能写入多份存放到Master机器的多个磁盘中防止某个磁盘损害),出现故障时需要人工介入。
-
第3题:
下面哪一类不属于分布式存储系统?()
- A、分布式文件系统
- B、磁盘阵列
- C、分布式表格系统
- D、分布式数据库
正确答案:B -
第4题:
分布式文件系统HDFS主要由哪些功能模块构成()。
- A、客户端模块
- B、元数据管理模块
- C、数据存储服务模块
- D、数据划分模块
正确答案:A,B,C -
第5题:
下面关于SPHINX描述不正确的是()
- A、SPHINX检索基于SQL
- B、SPHINX适用数据库存储数据
- C、SPHINX支持分布式检索
- D、SPHINX检索无需建立索引
正确答案:D -
第6题:
HDFS是一个不可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。
正确答案:错误 -
第7题:
下面关于AIX文件系统和逻辑卷的关系描述,哪个是正确的()。
- A、增加文件系统对应的逻辑卷的大小,也就增加了文件系统的大小
- B、删除文件系统时,不会删除文件系统对应的逻辑卷
- C、删除文件系统对应的逻辑卷时,不会删除文件系统
- D、增加文件系统大小,也就增加了文件系统对应的逻辑卷的大小
正确答案:D -
第8题:
问答题试述HDFS中的块和普通文件系统中的块的区别。正确答案: 在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位,恶如不是以字节为单位。
HDFS中的块,默认一个块大小为64MB,而HDFS中的文件会被拆分成多个块,每个块作为独立的单元进行存储。HDFS在块的大小的设计上明显要大于普通文件系统。解析: 暂无解析 -
第9题:
单选题以下对于HDFS描述不正确的是()。AHDFS是一个使用Java编写的分布式系统文件
BHDFS由NameNode、DataNode、Client组成
CHDFS不支持标准的POSIX文件系统接口
DHDFS支持对已有的数据进行修改
正确答案: B解析: 暂无解析 -
第10题:
单选题下面关于HDFS架构关键设计要点错误的是()。A支持回收站机制,以及副本数的动态设置机制
B数据存储以数据块为单位,存储在操作系统的HDFS文件系统上
C提供JAVAAPI,HTTP方式,SHELL方式访问HDFS数据
DHDFS对外仅呈现多个统一的文件系统
正确答案: A解析: 暂无解析 -
第11题:
多选题分布式文件系统HDFS主要由哪些功能模块构成()A客户端模块
B数据划分模块
C数据存储服务模块
D元数据管理模块
正确答案: A,B解析: 暂无解析 -
第12题:
多选题HDFS其除具备其它分布式文件系统相同特性外,还有自己特有的特性,以下哪些是他的特性()?A高容错性
B高吞吐量
C高随机性
D大文件存储
正确答案: B,C解析: 暂无解析 -
第13题:
Hadoop的HDFS是一种分布式文件系统,适合高容错、高吞吐量场景的数据存储和管理。()此题为判断题(对,错)。
参考答案:对 -
第14题:
下列选项中,正确描述Flume对数据源的支持的是?()
A.只能使用HDFS数据源
B.可以配置数据源
C.不能使用文件系统
D.不能使用目录方式
B
-
第15题:
hadoop中的hdfs是分布式()
- A、计算框架
- B、存储系统
- C、中介系统
- D、网络系统
正确答案:B -
第16题:
Hadoop分布式文件系统(HDFS)具有()的特性。
- A、适合数据批量处理
- B、数据处理能力极强
- C、最大化吞吐率
- D、允许计算向数据迁移
- E、适合多线程问题
正确答案:A,C,D -
第17题:
下列关于/etc/fstab文件描述,以下正确的是()。
- A、fstab文件只能描述属于linux的文件系统
- B、CROM和软盘必须是自动加载的
- C、fstab文件中描述的文件系统不能被卸载
- D、启动时按fstab文件描述内容加载文件系统
正确答案:D -
第18题:
HBase是一个构建在HDFS上的分布式列存储系统。
正确答案:正确 -
第19题:
单选题下面哪一类不属于分布式存储系统?()A分布式文件系统
B磁盘阵列
C分布式表格系统
D分布式数据库
正确答案: B解析: 暂无解析 -
第20题:
多选题Hadoop的HDFS是一种分布式文件系统,适合以下哪种场景的数据存储和管理?()A大量小文件存储
B高容错,高吞吐量
C低延迟读取
D流式数据访问
正确答案: C,B解析: 暂无解析 -
第21题:
判断题HDFS是一个不可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。A对
B错
正确答案: 对解析: 暂无解析 -
第22题:
多选题Hadoop分布式文件系统(HDFS)具有()的特性。A适合数据批量处理
B数据处理能力极强
C最大化吞吐率
D允许计算向数据迁移
E适合多线程问题
正确答案: E,C解析: 暂无解析 -
第23题:
单选题下面关于SPHINX描述不正确的是()ASPHINX检索基于SQL
BSPHINX适用数据库存储数据
CSPHINX支持分布式检索
DSPHINX检索无需建立索引
正确答案: A解析: 暂无解析 -
第24题:
单选题HDFS除具备其它分布式文件系统相同特性外,特有的特性是()。A高容错性
B高吞吐量
C大文件存储
D以上都是
正确答案: B解析: 暂无解析