
niusouti.com
问答题阅读以下说明和流程图,将应填入____处的字句写在答题纸的对应栏内。下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图8-17中,i为字符串A中当前正在进行比较的动态子串首字符的下标,j为字符串B
题目
相似考题
更多“问答题阅读以下说明和流程图,将应填入____处的字句写在答题纸的对应栏内。下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中nm≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图8-17中,i为字符串A中当前正在进行比较的动态子串首字符的下标,j为字符串B的”相关问题
-
第1题:
函数String(n,字符串)的功能是( )。
A.把数值型数据转换为字符串
B.返回由n个字符组成的字符串
C.从字符串中取出n个字符
D.从字符串中第n个字符的位置开始取子字符串
正确答案:B
-
第2题:
阅读以下技术说明和流程图,根据要求回答问题1至问题3。
[说明]
图4-8的流程图所描述的算法功能是将给定的原字符串中的所有前部空白和尾部空白都删除,但保留非空字符。例如,原字符串“ FileName ”,处理变成“File Name”。图4-9、图4-10和图4-11分别详细描述了图4-8流程图中的处理框A、B、C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1)、ch(2)、…、ch(n)中,字符常量 KB表示空白字符。
图4-8所示的流程图的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i)、……、ch(j)依次送入ch(1)、ch(2)、……中。如果字符串中没有字符或全是空白字符,则输出相应的说明。
在图4-8流程图中,strlen()是取字符串长度函数。
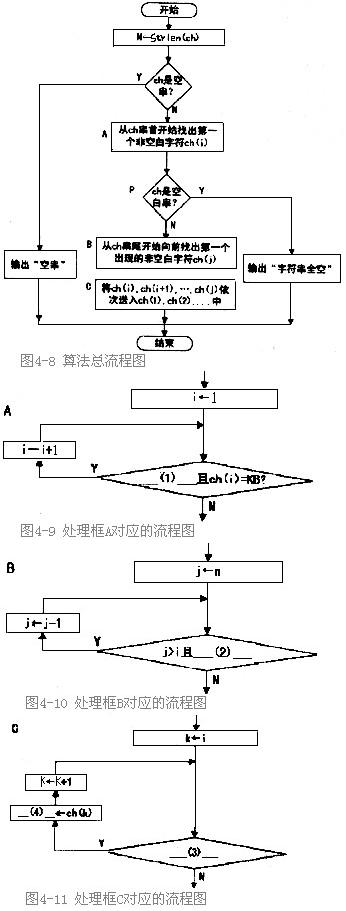
请将图4-9、图4-10和图4-11流程图中(1)~(4)空缺处的内容填写完整。
正确答案:本题用分层的流程图形式描述给定的算法。图4-8所描述的流程图是顶层图其中用A、B、C标注了 3个处理框。而图4-9、图4-10和图4—11所描述的流程图分别对这3个处理框进行了细化。 处理框A的功能是依次检查ch(1)ch(2)……(即从串首开始查找)直到找到非空白字符ch(i)。在图4-9所描述的流程图中对i=12……进行循环只要未找到字符串尾部标志(即"\0")且ch(i)为空白字符(KB)那么还需要继续查找。因此(1)空缺处所填写的内容是“i=n”或“n>=i”或其他等价形式。 处理框B的功能是依次检查ch(n)ch(n-1)……(即从串尾向前开始查找)直到找到非空字符ch(j)。在图4-10所描述的流程图中对j=nn-1……进行循环只要ch(j)=KB(空白字符)那么还需要继续循环查找。由于B框处理的前提是A框中已经找到了非空字符ch(i)因此循环最多到达“j=i”处就会结束。可见(2)空缺处所填写的判断条件是“ch(j)=KB”。而图4-10中的判断条件“j>i”是可有可无的。 处理框C的功能是将ch(i)ch(i+1)…ch(j)的内容依次送入ch(1)ch(2)……中。在图4-11所描述的流程图中对kf=ii+l…j进行循环只要满足“k=j”的条件就要继续循并环做传送处理因此(3)空缺处所填写的内容是“k=i”或其等价形式。 由于ch(i)应送往ch(1)ch(i+1)应送往ch(2)……因此ch(k)应送往ch(k-i+1)。这是程序员应熟练掌握的基本功即从几个特例寻找普遍规律再用特例代进去试验是否正确。因此(4)空缺处所填写的内容是“ch(k-i+1)”。
本题用分层的流程图形式描述给定的算法。图4-8所描述的流程图是顶层图,其中用A、B、C标注了 3个处理框。而图4-9、图4-10和图4—11所描述的流程图分别对这3个处理框进行了细化。 处理框A的功能是依次检查ch(1),ch(2),……(即从串首开始查找),直到找到非空白字符ch(i)。在图4-9所描述的流程图中,对i=1,2……进行循环,只要未找到字符串尾部标志(即"\0"),且ch(i)为空白字符(KB),那么还需要继续查找。因此,(1)空缺处所填写的内容是“i=n”或“n>=i”或其他等价形式。 处理框B的功能是依次检查ch(n),ch(n-1),……(即从串尾向前开始查找),直到找到非空字符ch(j)。在图4-10所描述的流程图中,对j=n,n-1……进行循环,只要ch(j)=KB(空白字符),那么还需要继续循环查找。由于B框处理的前提是A框中已经找到了非空字符ch(i),因此循环最多到达“j=i”处就会结束。可见,(2)空缺处所填写的判断条件是“ch(j)=KB”。而图4-10中的判断条件“j>i”是可有可无的。 处理框C的功能是将ch(i),ch(i+1)…,ch(j)的内容依次送入ch(1),ch(2)……中。在图4-11所描述的流程图中,对kf=i,i+l,…,j进行循环,只要满足“k=j”的条件,就要继续循并环做传送处理,因此(3)空缺处所填写的内容是“k=i”或其等价形式。 由于ch(i)应送往ch(1),ch(i+1)应送往ch(2)……,因此,ch(k)应送往ch(k-i+1)。这是程序员应熟练掌握的基本功,即从几个特例,寻找普遍规律,再用特例代进去试验是否正确。因此,(4)空缺处所填写的内容是“ch(k-i+1)”。 -
第3题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
【说明】
下面流程图的功能是:在已知字符串A中查找特定字符串B,如果存在,则输出B串首字符在A串中的位置,否则输出-1。设串A由n个字符A(0),A(1),…,A(n-1)组成,串B由m个字符B(0),B(1),…,B(m-1)组成,其中n≥m>0。在串A中查找串 B的基本算法如下:从串A的首字符A(0)开始,取子串A(0)A(1)…A(m-1)与串B比较;若不同,则再取子串A(1)A(2)…A(m)与串B比较,依次类推。
例如,字符串“CABBRFFD”中存在字符子串“BRF”(输出3),不存在字符子串“RFD”(输出-1)。
在流程图中,i用于访问串A中的字符(i=0,1,…,n-1),j用于访问串B中的字符(j=0,1,…,m-1)。在比较A(i)A(i/1)…A(i+m-1)与B(0)B(1)…B(m-1)时,需要对 A(i)与B(0)、A(i+1)与B(1)、…、A(i+j)与B(j)等逐对字符进行比较。若发现不同,则需要取下一个子串进行比较,依此类推。
【流程图】
 正确答案:(1) j+1 (2) i+1 (3) 0 (4) i (5) -1
正确答案:(1) j+1 (2) i+1 (3) 0 (4) i (5) -1
(1) j+1 (2) i+1 (3) 0 (4) i (5) -1 解析:本题采用的是最简单的字符子串查找算法。
在串A中查找是否含有串B,通常是在串A中从左到右取逐个子串与串B进行比较。在比较子串时,需要从左到右逐个字符进行比较。
题中已设串A的长度为n,存储数组为A,动态指针标记为i;串B的长度为m,存储数组为B,动态指针标记为j。
如果用伪代码来描述这种算法的核心思想,则可以用以下的两重循环来说明。
外循环为:
Fori=0ton-mdo
A(i)A(i+1)...A(i+m-1)~B(0)B(1)...B(m-1)
要实现上述比较,可以采用内循环:
Forj=0tom-1do
A(i+j)~B(j)
将这两重循环合并在一起就是:
Fori = 0ton-1do
Forj = 0tom-1do
A(i+j)~B(j)
这两重循环都有一个特点:若发现比较的结果不相同时,就立即退出循环。因此,本题中的流程图可以间接使用循环概念。
初始时,i与j都赋值0,做比较A(i+j)~B(j)。
若发现相等,则继续内循环(走图的左侧),j应该增1,继续比较,直到j=m为止,表示找到了子串(应输出子串的起始位置i);若发现不等,则退出内循环,继续开始外循环(走图的右侧),j应恢复为0,i应增1,继续比较,直到i>n-m为止,表示不存在这样的子串(输出-1)。
在设计流程图时,主要的难点是确定循环的边界(何时开始,何时结束)。当难以确定边界值变量的正确性时,可以用具体的数值之例来验证。这是程序员应具备的基本素质。 -
第4题:
读以下说明和流程图,回答问题将解答填入对应栏。
[说明]
下面的流程图,用来完成求字符串t在s中最右边出现的位置。其思路是:做一个循环,以s的每一位作为字符串的开头和t比较,如果两字符串的首字母是相同的,则继续比下去,如果一直到t的最后一个字符也相同,则说明在s中找到了一个字符串t;如果还没比较到t的最后一个字符,就已经出现字符串不等的情况,则放弃此次比较,开始新一轮的比较。当在s中找到一个字符串t时,不应停止寻找(因为要求的是求t在s中最右边出现位置),应先记录这个位置pos,然后开始新一轮的寻找,若还存在相同的字符串,则更新位置的记录,直到循环结束,输出最近一次保存的位置。如果s为空或不包含t,则返回-1。
注:返回值用pos表示。

[问题]
将流程图的(1)~(5)处补充完整。
正确答案:(1) pos=-1; (2) s[i]!='\0'; (3) s[j]=t[k]; (4) k>0; (5) pos=i;
(1) pos=-1; (2) s[i]!='\0'; (3) s[j]=t[k]; (4) k>0; (5) pos=i; 解析:本试题考查流程图。
题目中说明,如果s中不包含t,则返回-1,由流程图可以看出,如果(2)的条件不满足,流程图会直接跳到最后Returnpos,所以,在开始进行查找之前,就要先将pos置-1,所以(1)填入“pos=-1”。循环开始,(2)保证的条件应该是s[i]不是空的,即(2)填入“s[i]!='\0'”。下面就开始进行比较,由于要输出的是最右边出现的位予,所以当第一次比较到相同的字符时不能输出,只要暂时把保存着,即(5)填入“pos=i”,然后进行下一次循环,当又出现相同的字符串时,就将pos的值更新,如果一直到最后都没有再次出现相同的字符串,就把pos输出。当比较到第一个相同的字符时,要继续比较下去,看是不是t和s的每一个字符全相同,所以(3)应填入“s[j]=t[k]”。在什么情况下能说明t和s完全相同呢?就是当t一直比较到最后一个字符即空格时,并且k大于0(因为如果k等于0,则说明第一个字母就不相同,根本没有开始比较),所以(4)应填入“k>0”。 -
第5题:
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入对应栏内。
[说明]
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中,n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i为字符串A中当前正在进行比较的动态予串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
[流程图]
 正确答案:0-k i+j i+m i+1 i
正确答案:0-k i+j i+m i+1 i
0-k i+j i+m i+1 i 解析:本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果K就是文章字符串A中出现关键词字符串B的次数。显然,流程图开始时应将K赋值0,以后每找到一处出现该关键词,就执行增1操作K=K+1。
因此(1)处应填0→K。
字符串A和B的下标都是从0开始的。所以在流程图执行的开始处,需要给它们赋值0。接下来执行的第一个小循环就是判断A(i),A(i+1),…,A(i+j-1)是否完全等于B(0),B(1),…,B(m-1),其循环变量j=0,1,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是A(i+j)=B(j)且jm。只要遇到A(i+j)≠B(j)或者j=m(关键词各字符都己判断过)就不再继续执行该循环了。因此流程图的(2)处应填州i+j。
许多考生在(2)处填i,当j增1变化后,仍然使用A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在j=0,1,…,m-1时全都成立A(i+j)=B(j)(找到了一处关键词),直到j=m时才结束小循环;二是在jm时就发现了字符不等的情况,这说明此处并不出现关键词。因此流程图中用jm来区分找到与没有找到关键词的两种情况。
对于j=m,已找到一处关键词的情况,显然应该执行k=k+1,对关键词出现次数的变量k进行增1计算。同时,为了继续进行以后的判断,应将字符串A的下标i右移m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就使关键词的出现有可能发生部分重叠的现象。
流程图中,对于jm的情况,表示刚才判断关键词时并非各个字符都完全相同,也就是说,刚才的判断结论是此处并没有出现关键词。即A(i)开始的子串并不是关键词。因此,下次判断关键词应该以A(i+1)开始,即(4)处应填i+1。
在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对A(n-m),A(n-m+1),…,A(n-1)的判断。下标n-m来自从n-1倒数m个数。可以先试验写出A(n-m),A(n-m+1),…,A(n-1),再判断其个数是否为m。经检查,个数为(n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。
既然最后一次判断关键词应该是对A(n-m),A(n-m+1),…,A(n-1)的判断,即对i=n-m进行的小循环判断,所以当i>n-m时就应该停止大循环,停止再查找关键词了。
-
第6题:
阅读下列说明和流程图,将应填入(n)处。
[流程图说明]
流程图1-1描述了一个算法,该算法将给定的原字符串中的所有前导空白和尾部空白都删除,但保留非空字符之间的空白。例如,原字符串“ File Name ”,处理后变成“File Name”。流程图1-2、流程图1-3、流程图1-4分别详细描述了流程图1-1中的框A,B,C。
假设原字符串中的各个字符依次存放在字符数组ch的各元素ch(1),ch(2),…,ch(n)中,字符常量KB表示空白字符。
流程图1-1的处理过程是:先从头开始找出该字符串中的第一个非空白字符ch(i),再从串尾开始向前找出位于最末位的非空白字符ch(j),然后将ch(i),…,ch(j)依次送入 ch(1),ch(2),…中。如果原字符串中没有字符或全是空白字符,则输出相应的说明。在流程图中,strlen是取字符串长度函数。
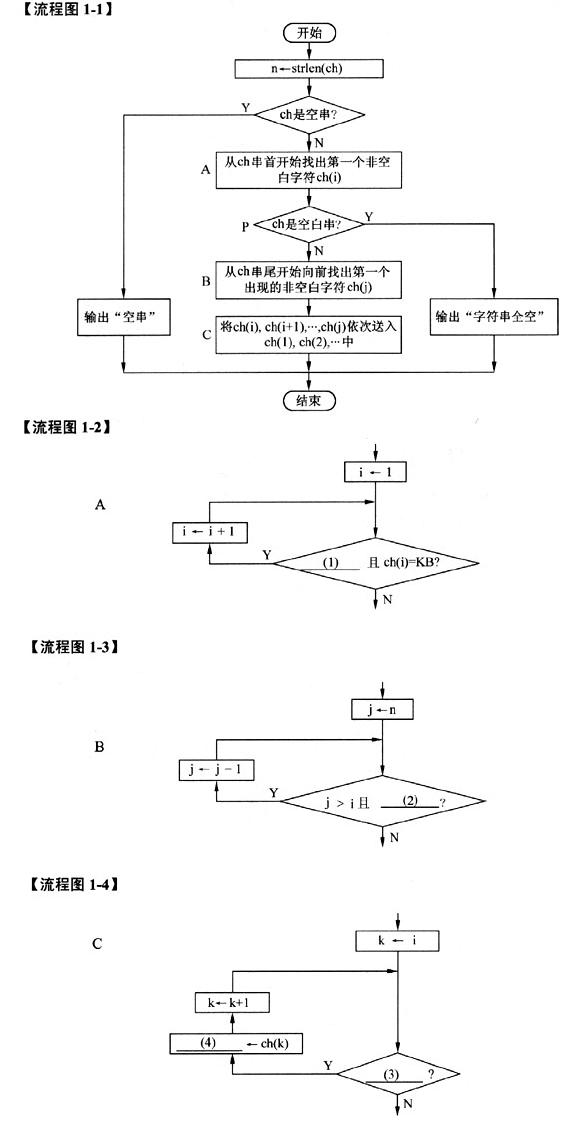
[问题]在流程图1-1中,判断框P中的条件可表示为:
i>(5)
正确答案:(1) i=n 或其等价形式 (2) ch(j)=KB (3) k=j 或其等价形式 (4) ch(k-i+1) (5) n
(1) i=n, 或其等价形式 (2) ch(j)=KB (3) k=j, 或其等价形式 (4) ch(k-i+1) (5) n 解析:本题用分层的流程图形式描述给定的算法。流程图1-1是顶层图,其中用A、B、C标注了三个处理框。而流程图1-2、图1-3、图1-4分别对这三个处理框进行了细化。
A框的功能是依次检查ch(1),ch(2),…,直到找到非空白字符ch(i)。流程图1-2中,对i=1,2,…进行循环,只要尚未找到尾,而且ch(i)=KB,则还需要继续查找。因此,(1)处可填写i=n (n>=i是其等价形式)。
B框的功能是依次检查ch(n),ch(n-1),…,直到找到非空字符ch(j)。流程图1-3中,对 j=n,n-1,…进行循环,只要ch(j)=KB,则还需要继续循环查找。由于B框处理的前提是A框中已经找到了非空字符ch(i),所以,循环最多到达j=i处就会结束。因此(2)处应填写判断条件ch(j)=KB。判断条件j>i是可有可无的。
C框的功能是将ch(i),ch(i+1),…,ch(j)的内容依次送入ch(1),ch(2),…中。流程图1-4中,对k=i,i+l,…,j进行循环,即只要k=j,就要继续做传送,继续循环。因此(3)处可填写k=j。
由于ch(i)应送往ch(1),ch(i+1)应送往ch(2),…,所以,ch(k)应送往ch(k-i+1)。这是程序员应熟练掌握的基本功:从几个特例,寻找普遍规律,再用特例代进去试验是否正确。因此,(4)处应填写ch(k-i+1)。
在流程图1-1中,判断ch是空白字符串,等价于A框处理结束后没有找到空白字符。从流程图1-2中可以看出,循环变量i超过n(或达到n+1)时,就说明从头到尾都找过了,仍没有找到空白字符。因此,(5)处可以填写n。 -
第7题:
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的
对应栏内。
【说明】
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾
依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程
处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。

??????
正确答案:
??流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。?本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相??应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=l,m循环,就是按已进出的关键词依次进行处理。接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。如果A(i)=K(j),则需要对计数器NK(j)增1.即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+I→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+l→m。更优的做法是先将计数器m增1,再执行A(j)→K(m)。因此(4)处应填m+l→m,(5)处应填A(i)。试题一参考答案(1)1(2)K(j)(3)Nk(j)+I→NK(j)或NK(j)十十或等价表示(4)m+l→m或m++或等价表示(5)A(i)?? -
第8题:
试题一(共15 分 )
阅读以下说明和流程图,将应填入 (n) 处的字句写在答题纸的对应栏内。
【 说明 】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在“aaaa”中只出现两次“aa”。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B 的下标,k为指定关键词出现的次数。
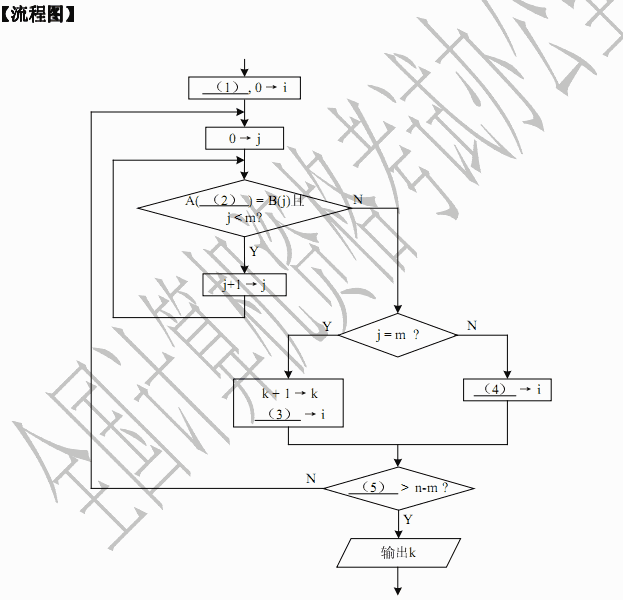 正确答案:
正确答案:
试题一参考答案(15分)注意:此题解答中的字母不区分大小写1,0→k,或k←0,或k=0,或等价形式3分2,i+j,或等价形式3分3,i+m或i+j,或等价形式3分4,i+1,或等价形式3分5,i3分 -
第9题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾依次分离出各个关键词{A(i)|i=1,…,n}(n>1)},其中包含了很多重复项,经下面的流程处理后,从中挑选出所有不同的关键词共m个{K(j)|j=1,…,m},而每个关键词K(j)出现的次数为NK(j),j=1,…,m。
[流程图]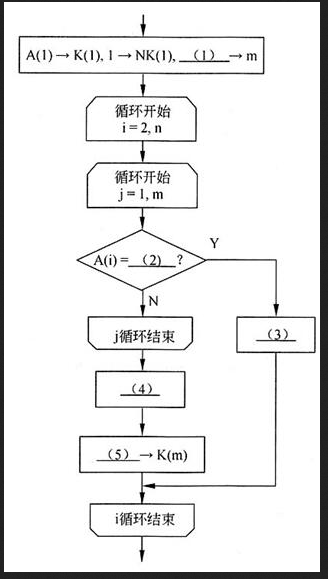 答案:解析:1
答案:解析:1
K(j)
NK(j)+1→NK(i) 或NK(j)++ 或等价表示
m+1→m或m++ 或等价表示
A(i)
【解析】
流程图中的第1框显然是初始化。A(1)→K(1)意味着将本书的第1个关键词作为选出的第1个关键词。1→NK(1)意味着此时该关键词的个数置为1。m是动态选出的关键词数目,此时应该为1,因此(1)处应填1。
本题的算法是对每个关键词与已选出的关键词进行逐个比较。凡是遇到相同的,相应的计数就增加1;如果始终没有遇到相同关键词的,则作为新选出的关键词。
流程图第2框开始对i=2,n循环,就是对书中其他关键词逐个进行处理。流程图第3框开始j=1,m循环,就是按己选出的关键词依次进行处理。
接着就是将关键词A(i)与选出的关键词K(j)进行比较。因此(2)处应填K(j)。
如果A(i)=K(i),则需要对计数器NK(j)增1,即执行NK(j)+1→NK(j)。因此(3)处应填NK(j)+1→NK(j)。执行后,需要跳出j循环,继续进行i循环,即根据书中的下一个关键词进行处理。
如果A(i)不等于NK(j),则需要继续与下个NK(j)进行比较,即继续执行j循环。如果直到j循环结束仍没有找到匹配的关键词,则要将该A(i)作为新的已选出的关键词。因此,应执行A(i)→K(m+1)以及m+1→m。更优的做法是先将计数器m增1,再执行A(i)→K(m)。因此(4)处应填m+1→m,(5)处应填A(i)。 -
第10题:
阅读以下说明和C函数,填补代码中的空缺,将解答填入答题纸的对应栏内。
[说明]
函数removeDuplicates(chai *str)的功能是移除给定字符串中的重复字符,使每种字符仅保留一个,其方法是:对原字符串逐个字符进行扫描,遇到重复出现的字符时,设置标志,并将其后的非重复字符前移。例如,若str指向的字符串为"aaabbbbscbsss",则函数运行后该字符串为"absc"。
[C代码] voidremoveDuplicates(char *str) { inti,len=strlen(str); /*求字符串长度*/ if(______)return; /*空串或长度为1的字符串无需处理*/ for(i=0;i<len;i++){ int flag=0; /*字符是否重复标志*/ int m; for(m=______; m<len;m++){ if(Str[i]==str[m]){ ______; break; } } if (flag) { int n,idx=m; /*将字符串第idx字符之后、与str[i]不同的字符向前移*/ for(n=idx+1; n<len; n++) if(Str[n]!=str[i]){ str[idx]=str[n];______; } str[______]='\0'; /*设置字符串结束标志*/ } } }答案:解析:len<2 或len<=1 或等价表示
i+1 或等价表示
flag=1 或给flag赋值为任何一个不是0的值
idx++ 或idx=idx+1 或等价表示
idx 或等价表示 -
第11题:
阅读以下说明和流程图,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
下面的流程图旨在统计指定关键词在某一篇文章中出现的次数。
设这篇文章由字符A(0),…,A(n-1)依次组成,指定关键词由字符B(0),…,B(m-1)依次组成,其中n>m≥1。注意,关键词的各次出现不允许有交叉重叠。例如,在"aaaa"中只出现两次"aa"。
该流程图采用的算法是:在字符串A中,从左到右寻找与字符串B相匹配的并且没有交叉重叠的所有子串。流程图中,i 为字符串 A 中当前正在进行比较的动态子串首字符的下标,j为字符串B的下标,k为指定关键词出现的次数。
【流程图】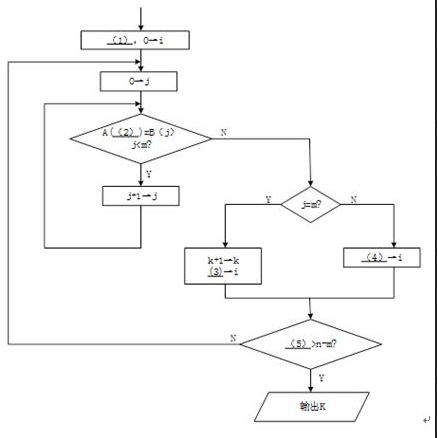 答案:解析:
答案:解析: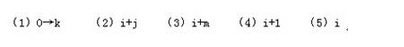
【解析】
本题考查用流程图描述算法的能力。
在文章中查找某关键词出现的次数是经常碰的问题。例如,为了给文章建立搜索关键词,确定近期的流行语,迅速定位文章的某个待修改的段落,判断文章的用词风格,甚至判断后半本书是否与前半本书是同一作者所写(用词风格是否一致)等,都采用了这种方法。
流程图最终输出的计算结果 k就是文章字符串 A中出现关键词字符串 B的次数。显然,流程图开始时应将 k赋值 0,以后每找到一处出现该关键词,就执行增1操作 k=k+1。因此(1)处应填0→k。
字符串 A和 B的下标都是从 0开始的。所以在流程图执行的开始处,需要给它们赋值 0。接下来执行的第一个小循环就是判断 A(i),A(i+1),…,A(i+j一1)是否完全等于 B(0),B(1),…,B(m一1),其循环变量j=0,l ,…,m-1。只要发现其中对应的字符有一个不相等时,该小循环就结束,不必再继续执行该循环。因此,该循环中继续执行的判断条件应该是 A(i+j)=B(j)且j许多考生在(2)处填 i,当j 增 1 变化后,仍然使用 A(i)进行比较就不对了。因此,在检查循环程序段时应多走查一次循环。
如果(2)处整体的判断条件不成立,则该判断关键词的小循环结束。此时可能有两种情况。一是在 j=0,1 ,…,m-1 时全都成立 A(i+j)=B(j)(找到了一处关键词),直到j=m 时才结束小循环;二是在 j对于 j=m,己找到一处关键词的情况,显然应该执行 k=k+1,对关键词出现次数的变量 k进行增 1计算。同时,为了继续进行以后的判断,应将字符串 A 的下标 i右移 m(这是因为题中假设关键词的出现不允许重叠)。因此(3)处应填写 i+m,表示应该从已出现的关键词后面开始再继续进行判断。由于此时的 j=m,书写i+j的答案也是正确的,但这不是程序员的好习惯,因为这不符合逻辑思维的顺势,在程序不断修改的过程中容易出错。不少考生在(3)处填写i+1,这意味着下次判断关键词将从A(i+1)开始,这就 使关键词的出现有可能发生部分重叠的现象。
流程图中,对于 j在下次判断关键词之前还应该判断是否全文已经判断完。最后一次小循环判断应该是对 A(n-m),A(n-m+1),… ,A(n一1)的判断。下标 n-m来自从 n-1 倒数 m个数。可以先试验写出A(n-m),A(n-m+1),… ,A(n一1),再判断其个数是否为m。经检查,个数为 (n-1)-(n-m)+1=m个,所以这是正确的。也可以用例子来检查次数是否正确。检查次数是程序员的基本功,数目的计算很容易少一个或多一个。 既然最后一次判断关键词应该是对A(n-m),A(n-m+1),… ,A(n一1)的判断,即对 i=n-m进行的小循环判断,所以当 i>n-m 时就应该停止大循环,停止再查找关键词了。 -
第12题:
函数String(n,"str")的功能是()。
- A、把数值型数据转换为字符串
- B、返回由n个字符组成的字符串
- C、从字符串中取出n个字符
- D、从字符串中第n个字符的位置开始取子字符串
正确答案:B -
第13题:
这程序有错吗?/*写一个函数,用来返回一个字符串中重复出现的最长字串的长度及其开始地址const char*p=NULL;int len=maxsubstr("qweohiuweyowohifpw",&p);输出:len=3,substr=ohi*/#include<stdio.h>#include<string.h>int maxsubstr(const char *str,const char **p){ int len=0,templen=0;//len为字符串中重复出现的最长字串的长度,templen为判断过程中字符串中重复出现的字串的长度 int size=strlen(str); const char*i=str,*j=0; //i=str即i=str[0],i指向字符串的第一个字符 for(i=str;i<str+size;i++){ //i依次指向字符串内的各个字符 const char *temp_i=i; //temp_i指向当前i所指字符 for(j=i+1;j<str+size;++j){ //j指向当前i所指字符的下一个字符,temp_i、j依次在总字符串中取两个字符串,temp_i在前,即在temp_i后寻找 与从temp_i开始的字符串重复长度最长的字符串 if(*temp_i==*j&&templen==0){ //此处前两个if可以合并,如果所指字符相同,temp_i往后指一个字符,j在第二个循环中会自动往后指(++j) ++templen; ++temp_i; } else if(*temp_i==*j&&templen!=0){ ++templen; ++temp_i; } else{ //当前所指字符不相等,temp_i需要指回i所指位置,j指回此次循环开始位置(由于for循环有++j,实际下次循环开始时往后指了一个) if(templen>len){ //判断重复出现的最长字串的长度是否改变 len=templen; templen=0; *p=i; }else{ templen=0; //就算重复出现的最长字串的长度不改变,当前长度也得清零。。。 } } } } return len;}int main(){ char str[10000]; const char*p=0; int len=0; int i=0; printf("输入带重复字符的字符串"); scanf("%s",str); len=maxsubstr(str,&p); printf("len=%d,substr=",len); for(i=0;i<len;i++){ printf("%c",*p++); } printf("\n");}
1.有错,因为给个重复的字符串,他的结果不正确 2.看不懂,所以自己编了个 #include <stdio.h> #include <string.h> void find_longest_repeat_str(const char str[], char longest_repeat_str[]); int main(int argc, char *argv[]) { char str[1024] = ""; char longest_repeat_str[1024] = ""; printf("输入字符串: "); scanf("%s", str); find_longest_repeat_str(str, longest_repeat_str); printf("The length of longest_repeat_str: %d\n", strlen(longest_repeat_str)); printf("Longest repeat string: %s\n", longest_repeat_str); return 0; } //找到最长的重复字符串 void find_longest_repeat_str(const char str[], char longest_repeat_str[]) { //原理:假设字符串是abcabcdabcdef,长度为13 int str_len = strlen(str); int i=0; char *j_pchar=NULL; char *k_pchar=NULL; //那么重复字符串的长度最长为13/2=6 //重复字符串的长度可能为6到1, for( i=str_len/2; i>=1; i-- ) { //当长度为6时,重复的字符串只可能由前13-6=7个字符组成, //重复的字符串的首地址只能为str+0到str+((13-6)-6) for(j_pchar=(char *)str; j_pchar<=str+str_len-i*2; j_pchar++) { //判断以j_pchar为首地址的字符串(长度为i), //是否在str后面部分有重复的.有重复的, //那么就找到了这个最长字符串 for(k_pchar=j_pchar+i; k_pchar<=str+str_len-i; k_pchar++) { if(strncmp(j_pchar, k_pchar, i)==0) { strncpy(longest_repeat_str, j_pchar, i); *(longest_repeat_str+i) = '\0'; return; } } } } *longest_repeat_str = '\0'; return; } -
第14题:
函数f_str(char *str,char del)的功能是;将非申字符串str分割成若干个子字符串并输出,del表示分割时的标志字符。例如,若str的值为“66981636666257”,del的值为“6”,调用此函数后,将输出3个子字符串,分别为“981”、“3”和“257”。请将函数f_str中(6)~(8)空缺处的内容填写完整。
[函数]
void f_str(char *str,char del)
{ int i,j,len;
len = strlen(str);
i = 0;
while (i<len) {
while ( (6) )
i++; /* 忽略连续的标志字符 */
/* 寻找从srt[i]开始直到标志字符出现的一个子字符串 */
j = i+1;
while (str[j] !=del && str[j] !='\0')
j++;
(7)="\0"; /* 给找到的字符序列置字符串结束标志 */
printf (" %s\t", & str [i]);
(8);
}
}
正确答案:函数f_str(char*strchar del)的功能是:将非空字符串str以分割标志字符为界线分割成若干个子字符串并输出。由函数说明和C代码可知该函数对给定的字符串进行从左至右的扫描找出不包含标志字符(变量del的值)的子字符串。在该函数C代码中变量i的初值为0len表示字符串的长度。当 ilen时进入循环体。如果当前字符(即str[i]的值)是标志字符则不做处理继续扫描以处理标志字符连成一串的情况。因此(6)空缺处所填写的内容是“str[i]==del”或其等价形式。 当退出第2个while循环时当前字符str[i]不是标志字符此时从str[i]开始继续寻找直到标志字符出现的…个子字符串(变量i保持不变用j标记寻找的过程)给找到的字符序列置字符串结束标志以便于后面语句的输出。因此(7)空缺处所填写的内容是“str[j]”。 printf输出语句结束之后就要继续寻找后面不包含标志字符的子字符串。此时需要把数组指针i移至j的后面再继续扫描。因此(8)空缺处所填写的内容是“i=j+1”。
函数f_str(char*str,char del)的功能是:将非空字符串str以分割标志字符为界线,分割成若干个子字符串并输出。由函数说明和C代码可知,该函数对给定的字符串进行从左至右的扫描,找出不包含标志字符(变量del的值)的子字符串。在该函数C代码中,变量i的初值为0,len表示字符串的长度。当 ilen时进入循环体。如果当前字符(即str[i]的值)是标志字符,则不做处理,继续扫描以处理标志字符连成一串的情况。因此(6)空缺处所填写的内容是“str[i]==del”或其等价形式。 当退出第2个while循环时,当前字符str[i]不是标志字符,此时从str[i]开始继续寻找,直到标志字符出现的…个子字符串(变量i保持不变,用j标记寻找的过程),给找到的字符序列置字符串结束标志,以便于后面语句的输出。因此(7)空缺处所填写的内容是“str[j]”。 printf输出语句结束之后,就要继续寻找后面不包含标志字符的子字符串。此时,需要把数组指针i移至j的后面,再继续扫描。因此(8)空缺处所填写的内容是“i=j+1”。 -
第15题:
阅读下列函数说明和C函数,将应填入______处的语句写在答题纸的对应栏内。
[函数2.1说明]
函数palindrome(char s[])的功能是:判断字符串s是否为回文字符串,若是,则返回0,否则返回-1。若一个字符串顺读和倒读都一样,称该字符串是回文字符串,例如,“LEVEL”是回文字符串,而“LEVAL”不是。
[函数2.1]
int palindrome(char s[])
{
char *pi, *pj;
pi=s;pj=s+strlen(s)-1;
while(pi<pj&& (1) ) {
pi++;pj--;
}
if( (2) ) return-1;
else return 0;
}
[函数2.2说明]
函数f(char *str,char del)的功能是:将非空字符串str分割成若干个子字符串并输出,del表示分割时的标志字符。
例如,若str的值为“33123333435”,del的值为“3”,调用此函数后,将输出3个子字符串,分别为“12”,“4”和“5”。
[函数2.2]
void f(char *str,char del)
{
int i,j,len;
len=strlen(str);
i=0;
While(i<len){
While( (3) )i++; /* 忽略连续的标志字符 */
/* 寻找从str[i]开始直到标志字符出现的一个子字符串 */
j=i+1;
while(str[j]!=del &&str[j]!'\0')j++;
(4) ='\0'; /* 给找到的字符序列置字符串结束标志 */
printf("%s\t",&str[i]);
(5);
}
}
正确答案:(1)*pi==*pj (2)pipj或 *pi != * pj及其等价形式 (3)str[i]==del (4)str[j] (5)i=j+1
(1)*pi==*pj (2)pipj或 *pi != * pj,及其等价形式 (3)str[i]==del (4)str[j] (5)i=j+1 解析:[函数2.1]
若一个字符串顺读和倒读都一样,称该字符串是回文字符串。如果使用数组s[n]来存储一个字符串,则根据这个定义,要判断一个串是否是回文字符串,需要循环比较:
(1)该字符串的第一个元素s[0]和最后一个元素s[n-1]比较,如果s[0]不等于 s[n-1],则s不是回文字符串。
(2)如果s[0]等于s[n-1],则第二个元素s[1]和倒数第二个元素s[n-2]比较,如果s[1]不等于s[n-2],则s不是回文字符串。
(3)依次类推,直到最中间的2个元素也比较完毕(如果s有偶数个元素),或者只剩下中间的1个元素(如果s有奇数个元素)。
当上述循环结束时,如果最中间的元素没有进行比较,就说明s不是回文字符串,如果进行了比较,则s是回文字符串。
在函数2.1中,pi和pj是2个指向字符的指针,程序首先将s的首地址赋给pi(即 pi=&a[0]),将元素s[strlen(s)-1)的地址赋给pj(即pj=&s[strlen(s)-1]),当pipj并且pi和pj所指向的字符相等时进行循环:pi自增,pj自减。
退出循环后,如果pipj,则s是回文字符串(如果s有偶数个元素,则为pi>pj,如果 s有奇数个元素,则为pi=pj);如果pipj,则s不是回文字符串。
[函数2.2]
由函数2.2说明可知,此函数对给定的字符串进行从左至右的扫描,找出不包含标志字符的子字符串。
在函数2.2中,i的初值为0,len表示字符串的长度。当ilen时进行循环:如果当前字符是标志字符,则不做处理,继续扫描以处理标志字符连成一串的情况。当退出该循环时,当前字符str[i]不是标志字符,这时开始寻找从str[i]开始,直到标志字符出现的一个子字符串(i保持不变,用j标记寻找的过程),给找到的字符序列置字符串结束标志,以便于后面语句的输出。
输出语句结束后,就要继续寻找后面的不包含标志字符的子字符串,这时需要把指针 i移动j的后面,继续扫描。 -
第16题:
阅读以下函数说明和C语言函数,将应填入(n)处的字句写在对应栏内。
【函数1说明】
函数palindrome(char s[])的功能是:判断字符串s是否为回文字符串。若是,则返回0,否则返回-1。若一个字符串顺读和倒读都一样时,则可称该字符串是回文字符串。例如,“LEVEL”是回文字符串,而“LEVAL”不是。
【函数1】
int palindrome(char s[]{
char *pi, *pj;
pi=s; pj=s+strlen(s)-1;
while(pi<pj&&(1)){
pi++; pj--;
}
if((2))return-1;
else return 0;
}
【函数2说明】
函数f(char *str, char del)的功能是:将非空字符串str分割成若干个子字符串并输出,del表示分割时的标志字符。
例如,若str的值为“33123333435”,del的值为“3”,调用此函数后,将输出三个子字符串,分别为“12”、“4”和“5”。
【函数2】
void f(char *str, char del){
int i,j, len;
len=strlen(str);
i=0;
while(i<len){
While((3)) i++; /*忽略连续的标志字符*/
/*寻找从str[i]开始直到标志字符出现的一个子字符串*/
j=i+1;
while(str[j]!=del && str[j]!='\0')j++;
(4)='\0'; /*给找到的字符序列置字符串结束标志*/
printf("%s\t",&str[i]);
(5);
}
}
正确答案:(1)*pi==*pi (2)pipj或*pi!=*pj (3)str[i]==del (4)str[j] (5)i=j+1
(1)*pi==*pi (2)pipj或*pi!=*pj (3)str[i]==del (4)str[j] (5)i=j+1 解析:本题考查在C语言中对字符串的处理。
【函数1】
使用数组s[n]来存储一个字符串,因为要根据回文字符串的定义来判断一个串是否是回文字符串,所以需要循环比较。
(1)拿该字符串的第一个元素s[0]和最后一个元素s[n-1]比较,如果s[0]不等于s[n-1],则s不是回文字符串。
(2)如果s[0]等于s[n-1],则拿第二个元素s[1]和倒数第二个元素s[n-2]比较,如果 s[1]不等于s[n-2],则s不是回文字符串。
(3)依次类推,直到最中间的两个元素也比较完毕(如果s有偶数个元素),或者只剩下中间的一个元素(如果s有奇数个元素)。
当上述循环结束时,如果最中间的元素没有进行比较,就说明s不是回文字符串;如果进行了比较,则s是回文字符串。
在函数1中,pi和pj是两个指向字符的指针,程序首先将s的首地址赋给pi(即*pi =a[0]),将元素s[strlen(s)-1]的地址赋给pj(即*pj=s[strlen(s)-1]),当pipj并且pi和pj所指向的值相等时进行循环:pi自增,pj自减。
退出循环后,如果pipj,则s是回文字符串(如果s有偶数个元素,则为pi>pj;如果s有奇数个元素,则为pi=pj);如果pipj,则s不是回文字符串。
【函数2】
由函数2说明可知,此函数对给定的字符串进行从左至右的扫描,找出不包含标志字符的子字符串。
在函数2中,i的初值为0,len表示字符串的长度。当ilen时进行循环:如果当前字符是标志字符,则不作处理,继续扫描。当退出该循环时,当前字符str[i]不是标志字符,这时从str[i]开始寻找,直到找到在标志字符中出现的一个子字符串(i保持不变,用i标记寻找的过程),给找到的字符序列置字符串结束标志,以便于后面语句的输出。
输出语句结束后,就要继续寻找后面的不包含标志字符的子字符串,这时,需要把指针i移动至j的后面,继续扫描。 -
第17题:
下列给定程序中函数fun的功能是:统计substr所指的字符串在str所指的字符串中出现的次数。 例如,若字符串为aaas lkaaas,子字符串为as;则应输出2。 请改正程序中的错误,使它能得出正确的结果。 注意:部分源程序在文件MODll.C中,不得增行或删行,也不得更改的程序的结构!

 正确答案:
正确答案:
【参考答案】

【考点分析】
本题考查:for循环语句的格式,for循环语句使用最为灵活,其一般形式为:for(表达式1;表达式2;表达式3),注意表达式之间使用”;”相隔;if条件语句的格式,其中if关键字需要区别大小写,这里不能混淆使用。关键字是由C语言规定的具有特定意义的字符串,也称为保留字。用户定义的标识符不应与关键字相同,并且关键字应小写。
【解题思路】
先看循环条件for(i=0,str[i],i++),不难发现此处for循环语句的格式有误,其中表达式之间应以”;”相隔;同时很容易发现if条件语句处的关键字书写错误。 -
第18题:
阅读下列说明和C函数,填补C函数中的空缺,将解答填入答案纸的对应栏目内。 【说明】 字符串是程序中常见的一种处理对象,在字符串中进行子串的定位、插入和删除是常见的运算。 设存储字符串时不设置结束标志,而是另行说明串的长度,因此串类型定义如下: typedef struct ﹛ Char *str; //字符串存储空间的起始地址 int length; //字符串长 int capacity; //存储空间的容量 ﹜SString;
【函数1说明】 函数indexStr(S,T,pos)的功能是:在S 所表示的字符串中,从下标pos开始查找T所表示字符串首次出现的位置。方法是:第一趟从S中下标为pos、T中下标伟0的字符开始,从左往右逐个对于来比较S和T的字符,直到遇到不同的字符或者到达T的末尾。若到达T的末尾,则本趟匹配的起始下标pos为T出现的位置,结束查找;若遇到了不同的字符,则本趟匹配失效。下一趟从S中下标pos+1处的字符开始,重复以上过程。若在S中找到T,则返回其首次出现的位置,否则返回-1。 例如,若S中的字符为伟”students ents”,T中的字符串伟”ent",pos=0,则T在S中首次出现的位置为4。 【C函数1】 int index Str(SString S ,SString T,int pos) ﹛ int i,j: i (S.length<1||T.length<1||pos+T.length-1) return-1; for(i=pos,j=0;i<S.length &&j<T.length;)﹛ if (S.str[i]==T.str[j])﹛ i++;j++; ﹜ else﹛ i=( 1 );j=0 ﹜ ﹜ if ( 2 )return i -T.length; return-1; ﹜ 【函数2说明】 函数 eraseStr(S,T}的功能是删除字符串S中所有与T相同的子串,其处理过程为: 首先从字符串 S 的第一个字符(下标为0)开始查找子串T,若找到〈得到子串在S中的起始位置),则将串 S 中子串T之后的所有字符向前移动,将子串T覆盖,从而将其删除,然后重新开始查找下一个子串T,若找到就用后面的宇符序列进行覆盖,重复上述过程,直到将S中所有的子串T删除。 例如,若字符串 S为 “12ab345abab678”、T为“ab”。第一次找到“ab”时(位置为2),将“345abab678”前移,S 中的串改为“12345abab678” ,第二次找到“ab”时(位置为 5);将“ab678”前移,S中的串改为“12345ab678”,第三次找到“ab”时(位置为5);将“678”前移 ,S中的串改为“12345678 ”。 【C函数2】 Void eraseStr(SString*S,SStringT) ﹛ int i; int pos; if (S->length<1||T.length<1||S->length<T.length) return; Pos=0; for(;;)﹛ //调用indexStr在S所表示串的pos开始查找T的位置 Pos=indexStr( 3 ); if(pos=-1) //S所表示串中不存在子串T return; for(i=pos+T.length;i<S->length;i++) //通过覆盖来删除自串T S->str[( 4 )]=S->str[i]; S->length=( 5 ); //更新S所表示串的长度 ﹜ ﹜
正确答案:(1)i+1
(2)j==T.length
(3)S,T,pos
(4)i-T.length(5)S ->length -T.length
-
第19题:
阅读以下说明和C函数,填补代码中的空缺(1)~(5),将解答填入答题纸的对
应栏内。
【说明】
函数removeDuplicates(char *str)的功能是移除给定字符串中的重复字符,使每种字
符仅保留一个,其方法是:对原字符串逐个字符进行扫描,遇到重复出现的字符时,设
置标志,并将其后的非重复字符前移。例如,若str指向的字符串为“aaabbbbscbsss”,
则函数运行后该字符串为“abse”。
【c代码】
void removeDuplicates (char *str)
int i,len = strlen (str); /*求字符串长度*/
If( (l) )return;/*空串或长度为1的字符串无需处理*l
for(i=0;i<len;i++) {
Int flag =O; /*字符是否重复标志*/
int m:
for(m =( 2 ); m<len; m++){
if(str[i]==str[m] ) {
__(3)_;break;
}
}
if (flag){
Int n,idx = m;
/*字符串第idx字符之后、与str [i]不同的字符向前移*/
For( n=idx+l; n<len. n++)
if ( str[n]!= str[i]) {
str[idx]= str[n]; (4);
}
Str[(5)]=\0; /* 设置字符串结束标志*/
}
}
}
正确答案:
本题考查C语言基本应用。题目要求在阅读理解代码说明的前提下完善代码。字符串的运算处理是c程序中常见的基本应用。根据注释,空(1)处应填入的内容很明确,为“len=1”或其等价表示。要消除字符串中的重复字符,需要扫描字符串,这通过下面的代码来实现:For(i=0;ilen;i++){intflag=Oj;/*字符是否重复标志*/intm:for(m=(2);m<len;m++)(if(str[i]==str[m]{(3),break;}*}......上面代码中.循环变量i用于顺序地记下字符串中每个不同字符首次出现的位置,那么后面的处理就是从i的下一个位置开始,考查后面的字符中有没有与它相同的(str[i]=sir[m]),因此空(2)应填入“i+l”或其等价表示。显然,当发现了重复字符时,应设置标志,空(3)处应填入“flag=l”或者给flag赋值为任何一个不是0的值。根据说明,发现与str[i]相同的第一个字符str[m]后,需要将其后所有与str[i]不同的字符前移,以覆盖重复字符str[m],对应的代码如下;if(flag){intn,idx=m;/*将字符串第idx字符之后、与str[1]不同的字符向前移*/for(n=idx+l,n<len.n++)if(str[n]!=str[i]}{str[idx]=str[n];(4)}Str[(5)]=’\0’;/*设置字符串结束标志*/}初始时,idx等于m,使str[n]覆盖str[idx]后,需要将idx自增,以便将后面与str[i]不同的字符继续前移,因此空(4)处应填入“idx++”或等价表示。由于后面字符前移了,所以字符串结束标志也需重新设置,空(5)处应填入“idx”。试题二参考答案(1)len2或len=l或等价表示(2)i+1或等价表示(3)flag=l或给flag赋值为任何一个不是O的值(4)idx++或idx=idx+l或等价表示(5)idx或等价表示 -
第20题:
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
下面流程图的功能是:在给定的两个字符串中查找最长的公共子串,输出该公共子串的长度L及其在各字符串中的起始位置(L=0时不存在公共字串)。例如,字符串"The light is not bright tonight"与"Tonight the light is not bright"的最长公共子串为"he light is not bright",长度为22,起始位置分别为2和10。
设A[1:M]表示由M个字符A[1],A[2],…,A[M]依次组成的字符串;B[1:N]表示由N个字符B[1],B[2],…,B[N]依次组成的字符串,M≥N≥1。
本流程图采用的算法是:从最大可能的公共子串长度值开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串,即在A、B字符串中分别顺序取出长度为L的子串后,调用过程判断两个长度为L的指定字符串是否完全相同(该过程的流程略)。
[流程图] 答案:解析:N或rnin(M,N)
答案:解析:N或rnin(M,N)
M-L+1
N-L+1
L-1
L,I,J
【解析】
本题考查对算法流程图的理解和绘制能力。这是程序员必须具有的技能。
本题的算法可用来检查某论文是否有大段抄袭了另一论文。"The light is not bright tonight"是著名的英语绕口令,它与"Tonight the light is not bright"大同小异。
由于字符串A和B的长度分别为M和N,而且M≥N≥1,所以它们的公共子串长度L必然小于或等于N。题中采用的算法是,从最大可能的公共子串长度值L开始逐步递减,在A、B字符串中查找是否存在长度为L的公共子串。因此,初始时,应将min(M,N)送L,或直接将N送L。(1)处应填写N或min(M,N),或其他等价形式。
对每个可能的L值,为查看A、B串中是否存在长度为L的公共子串,显然需要执行双重循环。A串中,长度为L的子串起始下标可以从l开始直到M-L+1(可以用实例来检查其正确性);B串中,长度为L的子串起始下标可以从1开始直到N-L+1。因此双重循环的始值和终值就可以这样确定,即(2)处应填M-L+1,或等价形式;(3)处应填N-L+1或等价形式(注意循环的终值应是最右端子串的下标起始值)。
A串中从下标I开始长度为L的子串可以描述为A[I:I+L-1];B串中从下标J开始长度为L的子串可以描述为A[J:J+L-1]。因此,双重循环体内,需要比较这两个子串(题中采用调用专门的函数过程或子程序来实现)。
如果这两个子串比较的结果相同,那么就已经发现了A、B串中最大长度为L的公共子串,此时,应该输出公共子串的长度值L、在A串中的起始下标I、在B串中的起始下标J。因此,(5)处应填L,I,J(可不计顺序)。
如果这两个子串比较的结果不匹配,那么就需要继续执行循环。如果直到循环结束仍然没有发现匹配子串时,就需要将L减少1((4)处填L-1或其等价形式)。只要L非0,则还可以继续对新的L值执行双重循环。如果直到L=0,仍没有发现子串匹配,则表示A、B两串没有公共子串。 -
第21题:
以下关于字符串的叙述中,正确的是( )。A.字符串属于线性的数据结构
B.长度为0字符串称为空白串
C.串的模式匹配算法用于求出给定串的所有子串
D.两个字符串比较时,较长的串比较短的串大答案:A解析:本题考查数据结构基础知识。
选项A是正确的。一个线性表是n个元素的有限序列(n≥0)。由于字符串是由字符构成的序列,因此符合线性表的定义。
选项B是错误的。长度为0字符串称为空串(即不包含字符的串),而空白串是指由空白符号(空格、制表符等)构成的串,其长度不为0。
选项C是错误的。串的模式匹配算法是指在串中查找指定的模式串是否出现及其位置。
选项D是错误的。两个字符串比较时,按照对应字符(编码)的大小关系进行比较。 -
第22题:
【试题三】阅读下列说明和 C 函数,填补 C 函数中的空缺,将解答填入答案纸的对应栏目内。【说明】字符串是程序中常见的一种处理对象,在字符串中进行子串的定位、插入和删除是常见的运算。设存储字符串时不设置结束标志,而是另行说明串的长度,因此串类型定义如下:Typedef struct ﹛char*str //字符串存储空间的起始地址int length //字符串长int capacity //存储空间的容量﹜SString;【函数 1 说明】函数 indexStr(S,T,pos)的功能是:在 S 所表示的字符串中,从下标 pos 开始查找 T 所表示字符串首次出现的位置。方法是:第一趟从 S 中下标为 pos、T 中下标伟 0 的字符开始,从左往右逐个对于来比较 S 和 T 的字符,直到遇到不同的字符或者到达 T 的末尾。若到达 T 的末尾,则本趟匹配的起始下标 pos 为 T 出现的位置,结束查找;若遇到了不同的字符,则本趟匹配失效。下一趟从 S 中下标 pos+1 处的字符开始,重复以上过程。若在 S 中找到 T,则返回其首次出现的位置,否则返回-1。例如,若 S 中的字符串伟″students ents″,T 中的字符串伟″ent″,pos=0,则 T 在 S 中首次出现的位置为 4。【C 函数 1】int indexStr(SString S ,SString T,int pos)﹛int i,j:if(S.length<1||S.length答案:解析:(1)i+1(2)j==T.length(3)S,T,pos(4)i-T.length(5)S ->length -T.length
【解析】
函数1为字符串匹配,算法为:先判断字符串S和T的长度,如果为空则不用循环,另外,如果字符串S的长度<字符串T的长度,那字符串S中也不能含有字符串T,也无需进行匹配。那当上述情况都不存在时,即需要进行循环。即从S的第一个字符开始,与T的第一个字符进行比较,如果相等,则S的第二个字符和T的第二字符进行比较,再相等就再往后移动一位进行比较,依次直到字符串T的结尾,也就是说j=T,.length。当某一个字符与T的字符不相等时,那么字符串S就往下移一位,再次进行与T的第一个字符进行比较,此时j恢复初始值,j=0。函数2为字符串的删除运算。首先,要调用函数 indexStr,需要三个参数,字符串S、字符串T和pos。然后删除的字符串的位置为删除初始点的位置到其位置点+字符串T的长度,并将后面的字符串前移。而删除T字符串后,字符串S的总长度变化,需减去字符串T的长度。 -
第23题:
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。
【说明】 计算两个字符串x和y的最长公共子串(Longest Common Substring)。 假设字符串x和字符串y的长度分别为m和n,用数组c的元素c[i][j]记录x中前i个字符和y中前j个字符的最长公共子串的长度。c[i][j]满足最优子结构,其递归定义为:

计算所有c[i][j](0 ≤i ≤ m,0 ≤j ≤ n)的值,值最大的c[i][j]即为字符串x和y的最长公共子串的长度。根据该长度即i和j,确定一个最长公共子串。【C代码】(1)常量和变量说明 x,y:长度分别为m和n的字符串 c[i][j]:记录x中前i个字符和y中前j个字符的最长公共子串的长度 max:x和y的最长公共子串的长度 maxi, maXj:分别表示x和y的某个最长公共子串的最后一个字符在x和y中的位置(序号) (2)C程序#include
< stdio.h>#include
< string.h>int c[50][50];int maxi;int maxj;int lcs(char
*x, int m, char *y, int n) { int i, j; int max= 0; maxi= 0; maxj = 0;for ( i=0;
i < =m ; i++) c[i][0] = 0;for (i =1;
i < = n; i++) c[0][i]=0;for (i =1;
i < = m; i++) { for (j=1; j < = n; j++) { if (
(1) ) {c[i][j] = c[i
-1][j -1] + 1;if(max < c[i][j])
{ (2)
; maxi = i; maxj =j; }}else (3)
; } } return max;}void
printLCS(int max, char *x) { int i= 0; if (max == 0) return; for (
(4) ; i < maxi; i++)printf("%c",x[i]);}void main( ){ char* x= "ABCADAB"; char*y= "BDCABA"; int max= 0; int m = strlen(x); int n = strlen(y); max=lcs(x,m,y,n); printLCS(max , x);}
【问题1】(8分)
根据以上说明和C代码,填充C代码中的空(1)~(4)。
【问题2】(4分)
根据题干说明和以上C代码,算法采用了 (5) 设计策略。
分析时间复杂度为 (6) (用O符号表示)。
【问题3】(3分)
根据题干说明和以上C代码,输入字符串x= "ABCADAB’,'y="BDCABA",则输出为 (7) 。答案:解析:【问题1】(8分)答案:(1)x[i-1]= =y[j-1] (2)max=c[i][j](3)c[i][j]=0 (4)i=maxi-max
【问题2】(4分)答案:动态规划、 O(m×n)或O(mn)
【问题3】(3分)答案:AB根据题干和C代码,计算出下表的值。
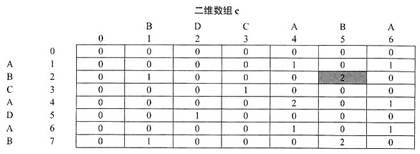
最大值为2。在计算过程中,我们记录第一个最大值,即表中阴影部分元素,因此得到最长公共子串为AB。